Bayesian Phylodynamics: Modeling Epidemic Spread from Genomic Data
This article provides a comprehensive overview of Bayesian phylodynamic methods for analyzing epidemic spread, tailored for researchers, scientists, and drug development professionals.
Bayesian Phylodynamics: Modeling Epidemic Spread from Genomic Data
Abstract
This article provides a comprehensive overview of Bayesian phylodynamic methods for analyzing epidemic spread, tailored for researchers, scientists, and drug development professionals. It covers foundational concepts, from basic Bayesian principles to advanced model selection, and details methodological applications using leading software like BEAST 2 and BEAST X. The content addresses critical troubleshooting aspects, including MCMC diagnostics and managing model identifiability, and presents validation through comparative case studies on pathogens like SARS-CoV-2 and PRRSV. By synthesizing theory and practical application, this guide aims to equip professionals with the knowledge to implement robust phylodynamic analyses for improving epidemic surveillance and informing public health interventions.
Bayesian Phylodynamics Foundations: From Core Concepts to Evolutionary Models
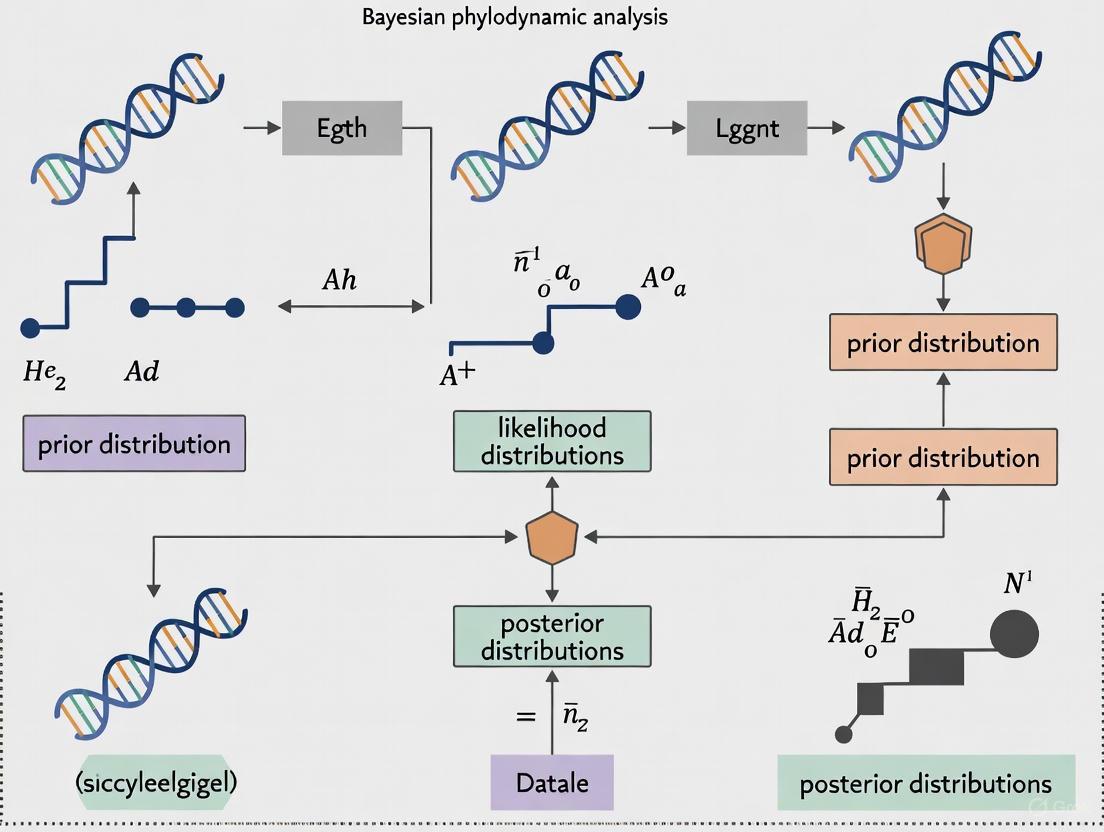
Bayesian statistics provides a powerful probabilistic framework for updating beliefs based on new evidence, making it particularly valuable for modeling complex evolutionary processes. Unlike frequentist approaches that calculate the probability of observing data given a hypothesis [1], Bayesian inference solves the "inverse probability" problem, enabling direct calculation of the probability of a hypothesis being true given the observed data [1]. This fundamental difference makes Bayesian methods exceptionally well-suited for phylogenetic analysis and phylodynamic modeling of epidemic spread, where researchers combine prior knowledge with new genetic data to infer evolutionary relationships and transmission dynamics.
The core of Bayesian inference revolves around three components: the prior distribution representing initial beliefs about parameters, the likelihood function describing the probability of observing the data given certain parameter values, and the posterior distribution representing updated beliefs after considering the evidence [2]. This Bayesian framework allows evolutionary biologists and epidemiologists to incorporate existing knowledge—such as previously estimated mutation rates or transmission parameters—while rigorously accounting for uncertainties in model parameters and phylogenetic tree topologies.
Core Principles: Prior, Likelihood, and Posterior
Mathematical Foundation
Bayesian inference is built upon Bayes' theorem, which formally describes the relationship between prior beliefs and posterior conclusions:
Posterior ∝ Likelihood × Prior
Expressed mathematically:
P(θ|X) = [P(X|θ) × P(θ)] / P(X)
Where:
- P(θ|X) is the posterior distribution of parameters θ given observed data X
- P(X|θ) is the likelihood of observing data X given parameters θ
- P(θ) is the prior distribution of parameters θ
- P(X) is the marginal likelihood of the data (a normalizing constant) [2]
In evolutionary biology, parameters θ might include evolutionary rates, divergence times, or tree topologies, while data X typically represents molecular sequences (DNA, RNA, or amino acids).
The Prior Distribution (P(θ))
The prior distribution encapsulates existing knowledge or assumptions about parameters before observing new data. Priors can range from uninformative (expressing minimal knowledge) to strongly informative (incorporating substantial previous evidence) [2]. In phylogenetic dating analyses, priors might include fossil calibration points or previously estimated mutation rates. For epidemic spread research, priors could incorporate known transmission dynamics from similar pathogens.
Table 1: Common Prior Distributions in Evolutionary Biology
| Distribution | Common Use Cases | Parameters |
|---|---|---|
| Beta(α,β) | Modeling probabilities, evolutionary rates | α, β > 0 |
| Gamma(k,θ) | Rate parameters, branch lengths | Shape k, scale θ |
| Dirichlet(α) | Stationary frequencies, substitution rates | Concentration vector α |
| Exponential(λ) | Simple priors for positive parameters | Rate λ |
| Uniform(a,b) | Uninformative priors for bounded parameters | Lower a, upper b |
The Likelihood Function (P(X|θ))
The likelihood function quantifies how probable the observed data are under different parameter values. In phylogenetics, this typically involves models of sequence evolution such as the General Time Reversible (GTR) model or its extensions [3]. For a phylogenetic tree τ with branch lengths t and substitution model parameters θ, the likelihood is calculated assuming sites evolve independently:
P(X|τ,t,θ) = Π P(X_i|τ,t,θ)
Where X_i represents the data at site i [4] [3]. Modern phylogenetic approaches often incorporate complex models accounting for rate variation across sites (Gamma distribution), heterotachy (lineage-specific rate variation), and other biological realities [3].
The Posterior Distribution (P(θ|X))
The posterior distribution represents the complete updated belief state about parameters after considering both prior knowledge and new evidence. This distribution is typically complex and high-dimensional, requiring computational methods like Markov Chain Monte Carlo (MCMC) for approximation [5] [3]. In phylodynamics, the posterior distribution might include joint estimates of transmission trees, evolutionary rates, and population dynamics.
Workflow and Computational Implementation
Bayesian Phylogenetic Analysis Pipeline
Figure 1: Bayesian phylogenetic inference workflow, showing the progression from data input to posterior distribution summarization.
MCMC Sampling and Convergence Diagnostics
Bayesian phylogenetic analysis typically employs Markov Chain Monte Carlo (MCMC) sampling to approximate the posterior distribution. Key considerations include:
- Chain Convergence: Assessing whether chains have reached the target distribution using statistics like Potential Scale Reduction Factor (PSRF) [3]
- Effective Sample Size (ESS): Ensuring sufficient independent samples from the posterior
- Burn-in: Discarding initial samples before chain convergence
- Proposal Mechanisms: Designing efficient moves for tree topology and parameter space exploration
Table 2: Essential Convergence Diagnostics for Bayesian Phylogenetics
| Diagnostic | Target Value | Interpretation |
|---|---|---|
| Potential Scale Reduction Factor (PSRF) | < 1.05 | Chains have converged to same distribution |
| Effective Sample Size (ESS) | > 200 | Sufficient independent samples |
| Trace Plot Inspection | Stationary and well-mixed | Visual confirmation of convergence |
| Autocorrelation Time | Low values preferred | Samples are sufficiently independent |
Application to Phylodynamic Analysis of Epidemic Spread
Integrating Epidemiological and Evolutionary Models
Phylodynamics combines epidemiological dynamics with phylogenetic inference to reconstruct transmission history and population dynamics of pathogens [5]. In this framework, Bayesian methods enable:
- Estimation of Key Epidemiological Parameters: Including reproduction numbers (R₀), rate of spread, and population sizes [5]
- Incorporation of Sampling Information: Accounting for uneven sampling across time and geography
- Uncertainty Quantification: Providing credible intervals for all estimated parameters
- Real-time Analysis: Updating estimates as new sequence data becomes available during outbreaks
The 2014 West African Ebola epidemic demonstrated the value of phylodynamic approaches, where Bayesian analysis of viral genomes provided insights into transmission dynamics and informed public health interventions [5].
Protocol: Bayesian Phylodynamic Analysis for Epidemic Research
Materials and Software Requirements
- Molecular sequence data (VCF or FASTA format)
- Sampling dates for tip-dating analysis
- Computational resources (high-performance computing for large datasets)
- Bayesian phylogenetic software (BEAST2, MrBayes, RevBayes)
Step-by-Step Procedure
- Data Preparation and Alignment
- Compile viral genome sequences with sampling dates
- Perform multiple sequence alignment (MAFFT, MUSCLE)
- Assess sequence quality and potential recombination
- Substitution Model Selection
- Compare nucleotide substitution models (HKY, GTR, etc.)
- Test for rate variation among sites (invariant sites, Gamma distribution)
- Select best-fitting model using Bayesian Information Criterion or similar metrics
- Clock Model Specification
- Choose among strict, relaxed, and random local clock models
- Assess clock-like behavior using root-to-tip regression
- Specify priors for clock rates based on previous estimates when available
- Tree Prior Selection
- Select appropriate population model (Coalescent, Birth-Death)
- Parameterize priors based on epidemiological context
- For epidemic spread, consider structured coalescent or birth-death skyline models
- MCMC Configuration
- Set appropriate chain length (typically 10⁷-10⁹ generations)
- Configure sampling frequency (every 1000-10000 generations)
- Specify initial values and proposal mechanisms
- Analysis and Diagnostics
- Run multiple independent MCMC chains
- Assess convergence using Tracer or similar tools
- Combine posterior samples after confirming convergence
- Posterior Summarization
- Generate maximum clade credibility trees
- Calculate posterior probabilities for tree topologies
- Compute highest posterior density intervals for parameters
Research Reagent Solutions for Bayesian Phylodynamics
Table 3: Essential Computational Tools for Bayesian Phylodynamic Analysis
| Tool/Software | Primary Function | Application Context |
|---|---|---|
| BEAST2 | Bayesian evolutionary analysis | Comprehensive phylodynamic inference with modular architecture |
| Tracer | MCMC diagnostics | Assessing convergence, effective sample sizes, parameter estimates |
| TreeAnnotator | Posterior tree summarization | Generating maximum clade credibility trees from posterior samples |
| FigTree | Tree visualization | Displaying time-scaled trees with posterior probabilities |
| MrBayes | Bayesian phylogenetic inference | MCMC sampling of phylogenetic trees and evolutionary parameters |
| RevBayes | Probabilistic graphical models | Flexible modeling for complex evolutionary hypotheses |
| IQ-TREE | Model selection and rapid inference | Efficient phylogeny inference with model testing capabilities [6] |
Advanced Modeling Considerations
Addressing Model Misspecification
Bayesian phylogenetic inference typically assumes characters evolve independently, though real morphological characters often exhibit correlations. Simulation studies demonstrate that Bayesian methods remain robust to violations of character independence for topological inference, though branch lengths may be underestimated under extreme rate heterogeneity [4]. Model extensions that integrate over character-state heterogeneity can partially correct these biases [4].
Incorporating Complex Evolutionary Patterns
Modern Bayesian phylogenetic approaches can accommodate various biological complexities:
- Heterotachy: Lineage-specific rate variation over time through covarion-style models [3]
- Rate Variation Across Sites: Gamma-distributed rate heterogeneity [3]
- Site-specific Selection: Branch-site models detecting episodic selection
- Recombination and Horizontal Gene Transfer: Phylogenetic network approaches
Protocol: Handling Character Correlation in Morphological Data
Background Morphological characters often exhibit logical, functional, or developmental correlations, violating the independence assumption of standard phylogenetic models [4].
Procedure
- Simulation Testing: Assess potential bias using parametric bootstrap or posterior predictive simulation
- Model Extension: Consider composite likelihood approaches or Markov models for character correlation
- Sensitivity Analysis: Compare results under independent and correlated models
- Prior Specification: Use conservative priors that account for potential model inadequacy
Validation Recent simulations show Bayesian inference assuming character independence accurately recovers tree topologies even when characters are strongly correlated, supporting continued use in morphological phylogenetics [4].
Future Directions and Methodological Advances
Bayesian methods in evolutionary biology continue to evolve, with promising research directions including:
- Integration with Machine Learning: Combining phylogenetic models with neural networks for improved parameter estimation [6]
- Multi-omic Data Integration: Joint analysis of genomic, transcriptomic, and phenotypic data within phylogenetic frameworks
- Real-time Phylodynamics: Developing efficient algorithms for near real-time analysis of emerging outbreaks
- Improved Computational Efficiency: Advanced MCMC techniques and variational inference for larger datasets
Despite these advances, challenges remain in model specification, computational efficiency, and interpretation of complex posterior distributions, particularly for high-dimensional phylogenetic models [3]. Ongoing methodological development focuses on addressing these limitations while expanding the biological realism of Bayesian phylogenetic models.
Phylodynamics, the study of the interaction between epidemiological and pathogen evolutionary processes, has become a fundamental building block for investigating the temporal and geographical origins, evolutionary history, and ecological risk factors associated with infectious disease spread [7]. Two well-established structured phylodynamic methodologies—based on the coalescent model and the birth-death model—are frequently employed to estimate viral spread between populations, operating under distinct assumptions that impact the accuracy of migration rate inference [8]. These models enable researchers to quantify past population dynamics from phylogenetic trees derived from molecular data, providing insights into epidemic spread that complement traditional epidemiological approaches.
The Bayesian phylodynamic inference framework BEAST2 is one of the primary software platforms within which such analyses are carried out, allowing researchers to jointly infer tree topologies, phylodynamic parameters, molecular clock rates, and substitution models via Markov Chain Monte Carlo (MCMC) sampling [9]. This integration provides a powerful approach for understanding and combating pandemics, as demonstrated during the SARS-CoV-2 pandemic, where phylogenetic and phylodynamic approaches were essential for quantifying international virus spread, identifying outbreaks and transmission chains, estimating growth rates and reproduction numbers, and tracking emerging variants [10].
Theoretical Foundation of Phylodynamic Models
The Structured Coalescent Model
The coalescent is a mathematical model of genealogies that describes the structure of genealogies generated by different demographic processes [11]. Under the neutral coalescent, the time between consecutive common ancestry events is modeled as a point process with a hazard rate that depends on the effective population size Nₑ(t) and the number of extant lineages in that interval A(t) at time t in the past. With time in units of the generation interval τ, this becomes proportional to A(t)/Nₑ(t) [11].
The coalescent model operates under the assumption that we have a small random sample from a large population, making it particularly suitable for analyzing endemic diseases with stable population dynamics [8] [12]. Originally, coalescent models were based on restrictive assumptions about the proportion of the population sampled and when taxa are sampled, but these assumptions have been relaxed since the coalescent was first introduced [11]. The model has been extended to consider heterogeneous structured populations, allowing researchers to investigate migration patterns between subpopulations [11].
A key advantage of coalescent approaches is that they require no explicit model of the sampling process, making them more robust when the sampling process deviates from simplistic assumptions [11]. However, estimates based on coalescent models may be biased by noisy demographic processes, and the model's performance can be compromised when population sizes change rapidly, such as during epidemic outbreaks [8].
The Multi-Type Birth-Death Model
The multi-type birth-death model is a linear birth-death process accounting for structured populations where individuals are classified into different types [9]. In this model, the probability density of a phylogenetic tree can be calculated by numerically integrating a system of differential equations. The process begins at time 0 with one individual of a specific type and evolves through time with individuals giving birth to additional individuals, migrating between types, dying, or being sampled according to specified rates [9].
Formally, the model with d types defines the process over time interval (0,T), partitioned into n segments through time points 0 < t₁ < ... < tₙ₋₁ < T. Each individual of type i at time t (where tₖ₋₁ ≤ t < tₖ) can [9]:
- Give birth to an additional individual of type j with birth rate λᵢⱼ,ₖ
- Migrate to type j with migration rate mᵢⱼ,ₖ (with mᵢᵢ,ₖ = 0)
- Die with death rate μᵢ,ₖ
- Be sampled with sampling rate ψᵢ,ₖ
At specific sampling times tₖ, each individual of type i is sampled with probability ρᵢ,ₖ. Upon sampling, the individual is removed from the infectious pool with probability rᵢ,ₖ [9]. This comprehensive framework allows for flexible modeling of complex population dynamics with changing parameters over time.
The birth-death model incorporates a model of the sampling process, which provides additional statistical power when the sampling process is correctly specified but may lead to bias if the sampling process is misspecified [11]. Recent improvements to birth-death model implementation in software packages like BEAST2's bdmm have dramatically increased the number of genetic samples that can be analyzed, improved numerical robustness, and extended model flexibility to include piecewise-constant changes in migration rates through time and sampling at multiple time points [9].
Quantitative Model Comparison
Table 1: Performance comparison of birth-death and coalescent models across epidemiological scenarios
| Epidemiological Scenario | Model Performance | Migration Rate Accuracy | Source Location Estimation |
|---|---|---|---|
| Epidemic Outbreaks | Birth-death model superior | More accurate regardless of migration rate | Comparable between models |
| Endemic Diseases | Comparable performance | Comparable accuracy; coalescent more precise | Comparable between models |
| Varying Population Sizes | Coalescent with constant size performs poorly | Inaccurate estimates | Robust in both models |
| Structured Populations | Multi-type birth-death excels | Accurate migration rate estimation | Both models perform well |
Recent research comparing these phylodynamic methodologies reveals distinct performance characteristics across different scenarios [8]. For epidemic outbreaks, the birth-death model exhibits a superior ability to retrieve accurate migration rates compared to the coalescent model, regardless of the actual migration rate. This advantage stems from the birth-death model's explicit accounting for population dynamics, which is crucial during exponential growth phases typical of outbreaks [8].
For endemic disease scenarios, where population sizes remain relatively constant, both models produce comparable coverage and accuracy of migration rates, with the coalescent model generating more precise estimates [8]. Regardless of the specific scenario, both models similarly estimate the source location of the disease, indicating robustness in identifying the geographical origin of outbreaks [8].
The choice between models also involves practical computational considerations. The structured birth-death model typically requires a model of the sampling process, whereas the coalescent makes no assumptions about how lineages are sampled through time [11]. This difference means that birth-death models may be biased by misspecification of the sampling process, while coalescent models may be biased by noisy demographic processes [11].
Application Protocols for Epidemic Research
Model Selection Workflow
Table 2: Decision framework for selecting appropriate phylodynamic models
| Research Objective | Recommended Model | Key Considerations | Software Implementation |
|---|---|---|---|
| Estimating migration rates during outbreaks | Multi-type birth-death | Accounts for exponential growth dynamics | BEAST2 with bdmm package |
| Endemic disease dynamics | Structured coalescent | Provides more precise estimates | BEAST2 with structured coalescent |
| Analyzing large datasets (>250 samples) | Improved birth-death models | Recent algorithmic improvements prevent numerical instability | BEAST2 with updated bdmm |
| Incorporating known sampling process | Birth-death with sampling model | Leverages additional information from sampling times | BEAST2 with appropriate sampling priors |
| Uncertain sampling process | Coalescent model | Robust to misspecification of sampling | BEAST2 with coalescent priors |
Protocol 1: Implementing Multi-Type Birth-Death Analysis
Purpose: To estimate migration rates and population dynamics during epidemic outbreaks using the multi-type birth-death model.
Materials and Reagents:
- Genetic sequence data (FASTA format): Minimum of 50 sequences per population for reliable estimates
- Temporal information: Sample collection dates for tip dating
- Population metadata: Geographic or host population labels for discrete traits
- Computational resources: BEAST2 software package with bdmm extension
- Reference files: Outgroup sequences for rooting if required
Procedure:
- Data Preparation:
- Align sequences using MAFFT or MUSCLE
- Partition data appropriately if using multi-gene datasets
- Format metadata in tab-separated files matching sequence names
Model Specification in BEAST2:
- Define population structure based on discrete traits
- Set birth rate prior: Exponential(1) or LogNormal(1,1.5)
- Set death rate prior: Often fixed based on external epidemiological data
- Specify sampling proportion prior: Beta(2,2) if unknown
- Configure migration rate prior: Exponential(1) for asymmetric migration
MCMC Configuration:
- Set chain length to at least 10⁷ iterations for complex models
- Configure log parameters every 10,000 iterations
- Set up path sampling for model comparison if needed
- Enable state logging for diagnostic purposes
Analysis Execution:
- Run multiple independent replicates to assess convergence
- Use BEAGLE library if available to accelerate computation
- Monitor effective sample sizes (ESS > 200 for all parameters)
Result Interpretation:
- Check convergence using Tracer software
- Summarize trees using TreeAnnotator
- Visualize migration rates using SpreadD3 or other visualization tools
Troubleshooting Tips:
- If ESS values remain low, increase chain length or adjust operator weights
- If numerical instability occurs with large datasets, use the updated bdmm implementation [9]
- If migration rates are poorly identified, consider simplifying population structure
Protocol 2: Structured Coalescent Analysis for Endemic Diseases
Purpose: To estimate population history and migration rates in endemic scenarios with stable population sizes.
Materials and Reagents:
- Genetic sequence data: Representative samples from each subpopulation
- Population structure definition: Clear criteria for subpopulation assignment
- Molecular clock model: Strict or relaxed clock based on evolutionary rate
- Substitution model: Selected through model testing (e.g., jModelTest)
Procedure:
- Data Preparation:
- Remove recombinant sequences using RDP or similar tools
- Select representative sequences to avoid oversampling clusters
- Verify temporal signal using root-to-tip regression
Model Specification in BEAST2:
- Select structured coalescent prior (constant or exponential growth)
- Define demographic model based on population history
- Set up discrete trait analysis for migration reconstruction
- Configure molecular clock model (strict or relaxed)
MCMC Configuration:
- Set appropriate chain length based on dataset size
- Adjust operators for efficient exploration of parameter space
- Configure tree and parameter logging intervals
Analysis Execution:
- Run analysis with appropriate computational resources
- Monitor convergence through multiple runs
- Validate results with complementary approaches
Result Interpretation:
- Summarize population size changes through time
- Estimate migration rates between subpopulations
- Identify source-sink dynamics if present
Validation Steps:
- Compare results with epidemiological surveillance data
- Assess robustness through sensitivity analyses
- Validate migration patterns with independent data sources
Case Studies in Epidemic Spread Research
SARS-CoV-2 Pandemic Investigations
Phylodynamic approaches played a crucial role in understanding and combating the early SARS-CoV-2 pandemic [10]. During the first year of the pandemic, nearly 400,000 full or partial SARS-CoV-2 genomes were generated and shared publicly, enabling unprecedented insights into viral spread dynamics.
Molecular clock dating of SARS-CoV-2 lineages using coalescent models indicated multiple introductions from Wuhan to Guangdong in early January 2020, with a subsequent fall in lineage diversity suggesting that within-country travel restrictions combined with comprehensive tracing and isolation were effective in controlling transmission [10]. Similarly, a birth-death skyline approach applied to Australian data estimated a national fall in the effective reproduction number (Rₜ) from 1.63 to 0.48 after the introduction of travel restrictions and social distancing on 27 March 2020 [10].
Phylogeographic studies investigating the impact of international travel restrictions consistently showed reduced numbers of introductions along international routes covered by travel restrictions [10]. For example, in South Africa, international introductions plummeted after travel restrictions began on 26 March 2020, while in Brazil, at least 104 international introductions were estimated during March and April 2020, arriving too early for subsequent restrictions to prevent domestic transmission establishment [10].
Table 3: Phylodynamic parameters estimated from early SARS-CoV-2 analyses
| Parameter | Estimate | 95% Interval | Model Used | Data Source |
|---|---|---|---|---|
| Evolutionary Rate | 0.80×10⁻³ | 0.14×10⁻³ – 1.31×10⁻³ | Coalescent exponential growth | 86 genomes [12] |
| TMRCA | 17-Nov-2019 | 27-Aug-2019 – 19-Dec-2019 | Coalescent exponential growth | 86 genomes [12] |
| Growth Rate | 35.38/year | 15.49 – 53.47 | Coalescent exponential growth | 86 genomes [12] |
| Doubling Time | 7.2 days | 4.7 – 16.3 | Coalescent exponential growth | 86 genomes [12] |
| Rₜ in Australia | 1.63 to 0.48 | N/A | Birth-death skyline | National data [10] |
| Rₜ in New Zealand | 7.0 to 0.2 | N/A | Birth-death model | Transmission cluster [10] |
Influenza A Virus Global Migration Patterns
The improved multi-type birth-death model algorithm was applied to two datasets of Influenza A virus HA sequences—one with 500 samples and another with only 175—to compare global migration patterns and seasonal dynamics [9]. This analysis demonstrated the information gain from analyzing larger datasets, which became possible with algorithmic changes to bdmm that dramatically increased the number of genetic samples that could be analyzed while improving numerical robustness and efficiency [9].
The study highlighted how birth-death models with sampling can quantify past population dynamics in structured populations based on phylogenetic trees, enabling researchers to infer rates at which species migrate between geographic regions or gain/lose traits of interest [9]. The comparison between datasets of different sizes showed how larger sample sizes led to improved precision of parameter estimates, particularly for structured models with a high number of inferred parameters [9].
The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential computational tools and resources for phylodynamic analysis
| Tool/Resource | Function | Application Context | Access Method |
|---|---|---|---|
| BEAST2 | Bayesian evolutionary analysis | Primary platform for phylodynamic inference | Open source [9] [12] |
| bdmm package | Multi-type birth-death model implementation | Structured population analysis | BEAST2 package [9] |
| MASTER | Birth-death process simulation | Model validation and simulation studies | Open source [11] |
| Tracer | MCMC diagnostic analysis | Assessing convergence and effective sample sizes | Open source [12] |
| TreeAnnotator | Tree summarization | Generating maximum clade credibility trees | Part of BEAST package [12] |
| FigTree | Tree visualization | Viewing and annotating phylogenetic trees | Open source [12] |
Advanced Methodological Considerations
Approximate Bayesian Computation for Complex Models
As phylodynamic models increase in complexity, traditional MCMC approaches can become computationally demanding and impractical for real-time outbreak analysis [13]. Recent advances in approximate Bayesian inference methods aim to balance inferential accuracy with scalability, including Approximate Bayesian Computation (ABC), Bayesian Synthetic Likelihood (BSL), Integrated Nested Laplace Approximation (INLA), and Variational Inference (VI) [13].
These approaches are particularly relevant for epidemiological applications where rapid updates are required during ongoing outbreaks. The development of hybrid exact-approximate inference methods represents a promising frontier that combines methodological rigor with the scalability needed for outbreak response [13]. Epidemiologists can use these approaches to navigate the trade-off between statistical accuracy and computational feasibility in contemporary disease modeling.
Addressing Sampling Biases and Model Misspecification
Both birth-death and coalescent models face challenges related to sampling biases and model misspecification. Birth-death models require a model of the sampling process, which can lead to bias if incorrectly specified [11]. Coalescent models, while not requiring explicit sampling models, may be biased by noisy demographic processes [11].
Research has shown that much of the statistical power of birth-death model approaches is derived from information in the sequence of sample times rather than the genealogy itself [11]. This finding suggests an enhancement to coalescent models: if the sampling process is known, researchers can augment the coalescent likelihood with a separate likelihood for the sequence of sample times, potentially improving precision [11].
For birth-death models, the BEAST2 package bdmm now allows for more flexible sampling scenarios, including homochronous sampling events at multiple time points (not only the present), individuals that are not necessarily removed upon sampling, and piecewise-constant changes in migration rates through time [9]. These enhancements address some of the limitations of earlier implementations and expand the range of empirical datasets that can be appropriately modeled.
Birth-death and coalescent models represent essential phylodynamic components for understanding population dynamics in infectious disease research. The choice between these modeling frameworks depends on the specific research question, epidemiological context, and data characteristics. For epidemic outbreaks with rapidly changing population sizes, multi-type birth-death models generally provide more accurate estimates of migration rates, while for endemic diseases with stable population dynamics, structured coalescent models offer comparable accuracy with greater precision [8].
Recent methodological advances, including improved algorithms for birth-death model inference [9] and enhanced coalescent approaches [11], have expanded the range of questions that can be addressed using phylodynamic methods. The continued development of approximate Bayesian computation techniques [13] promises to further increase the applicability of these approaches to complex, large-scale datasets characteristic of modern pathogen genomic surveillance.
As demonstrated during the SARS-CoV-2 pandemic [10], the integration of phylodynamic methods with traditional epidemiological approaches provides powerful insights into disease spread, intervention effectiveness, and spatial dynamics, making these tools indispensable for contemporary infectious disease research and public health response.
In the field of epidemic spread research, accurately quantifying key evolutionary parameters is essential for understanding pathogen dynamics and informing public health interventions. Two of the most critical metrics for tracking infectious disease evolution and spread are the effective population size (Nₑ) and the reproductive number (R). The effective population size represents the number of individuals in an idealized population that would exhibit the same amount of genetic drift or inbreeding as the actual population, providing insights into genetic diversity and adaptive potential [14]. The reproductive number, particularly the time-varying effective reproductive number (Rₜ), indicates the average number of secondary infections generated per infectious case at time t, serving as a crucial indicator of transmission intensity [15] [16].
Bayesian phylodynamic analysis has emerged as a powerful framework for integrating genetic, epidemiological, and evolutionary data to estimate these parameters. This approach leverages pathogen genomes to reconstruct evolutionary relationships and population dynamics, enabling researchers to uncover patterns of epidemic spread that are difficult to detect using traditional epidemiological methods alone [5] [17]. When evolutionary and epidemiological processes occur on similar timescales, as with rapidly evolving RNA viruses, genomic data carry a distinctive signature of epidemic dynamics that can be extracted through phylodynamic methods [5].
The following application notes and protocols provide detailed methodologies for estimating Nₑ and Rₜ within a Bayesian phylodynamic framework, specifically designed for researchers, scientists, and drug development professionals working on epidemic surveillance and control.
Estimating Effective Population Size (Nₑ)
Conceptual Foundation and Biological Significance
The effective population size (Nₑ) is a fundamental parameter in population genetics and evolutionary biology, originally introduced by Sewall Wright in the 1930s [18]. Nₑ quantifies the magnitude of genetic drift and inbreeding within populations, with important implications for understanding adaptive potential and genetic diversity loss. In pathogen evolution, Nₑ reflects the number of viruses effectively contributing to the next generation, which influences the rate of antigenic evolution, drug resistance development, and adaptive potential [14].
For epidemics, tracking changes in Nₑ through time can reveal important aspects of outbreak dynamics, including population bottlenecks during transmission events and expansion phases as epidemics spread through susceptible populations. Unlike the census population size, Nₑ accounts for variances in reproductive success among individuals, making it typically much smaller than the total number of infected hosts [14].
Methodological Approaches for Nₑ Estimation
Table 1: Methods for Estimating Effective Population Size (Nₑ) from Genomic Data
| Method Class | Principle | Software Tools | Temporal Scope | Key Considerations |
|---|---|---|---|---|
| Linkage Disequilibrium (LD) | Measures non-random association of alleles at different loci | NeEstimator2, SPEEDNe, GONE | Contemporary/Recent | Sensitive to sample size, marker density, population structure [14] [18] |
| Allele Frequency Spectrum (AFS) | Compares observed site frequency spectrum to theoretical expectations | δaδi, GADMA | Historical/Contemporary | Requires large sample sizes; sensitive to demographic model specification [14] |
| Coalescent-based | Models the time to most recent common ancestor (TMRCA) of sequences | PHLASH, SMC++, MSMC2 | Historical | Computational intensity varies; PHLASH shows improved accuracy for whole-genome data [19] |
| Phylogenetic | Estimates Nₑ from pathogen phylogenies | BEAST, MrBayes | Varies with timescale | Integrates evolutionary and epidemiological parameters [20] [17] |
Protocol: LD-based Nₑ Estimation Using NeEstimator2
Principle: This method estimates contemporary Nₑ from the observed linkage disequilibrium (LD) between unlinked loci, as LD accumulates more rapidly through genetic drift in smaller populations [14] [18].
Materials:
- Genotype data (SNP array or sequencing data)
- High-performance computing resources
- Population genetic software packages
Procedure:
Data Preparation and Quality Control
- Format genotype data in appropriate formats (e.g., PLINK, GENEPOP)
- Perform quality control filtering: remove loci with high missingness (>10%), significant deviation from Hardy-Weinberg equilibrium (p < 0.001), and minor allele frequency below 0.01 [18]
- For LD-based methods, prune markers in high linkage disequilibrium (r² > 0.5) to ensure locus independence [18]
Parameter Configuration
- Set critical allele frequency threshold (default: 0.05) to minimize bias from rare alleles
- Specify random mating model for epidemic pathogens
- Define confidence interval method (jackknifing recommended)
Execution
- Run NeEstimator2 with prepared input files
- Use command:
Ne2 -i input_file.gen -s 0 -o output_file.txt - For large datasets, utilize high-performance computing clusters
Interpretation of Results
- Examine point estimate and confidence intervals for Nₑ
- Compare estimates across different allele frequency thresholds to assess robustness
- Consider biological plausibility given epidemiological context
Troubleshooting:
- If confidence intervals are excessively wide, increase sample size or marker density
- If estimates are implausibly small, check for population stratification or sampling artifacts
- For very large populations, consider alternative methods as LD-based approaches have upper detection limits [14]
Determining Optimal Sample Size for Nₑ Estimation
Empirical studies indicate that a sample size of approximately 50 individuals often provides a reasonable approximation of the true Nₑ value, balancing cost and precision [18]. However, this should be adjusted based on:
- Population characteristics: Larger samples are needed for more diverse populations
- Marker density: Higher density SNP arrays or whole genome sequences may allow smaller sample sizes
- Research question: Higher precision required for detecting subtle changes over time
Estimating Reproductive Numbers (R)
Conceptual Framework
The reproductive number represents the transmissibility of an infectious pathogen in a population. Several related metrics are used in epidemiological practice:
- Basic reproduction number (R₀): The average number of secondary cases generated by a single infectious individual in a fully susceptible population
- Effective reproduction number (Rₜ): The time-varying counterpart to R₀, accounting for accumulating immunity and interventions [15] [16]
- Spatiotemporal reproduction number: An extension that incorporates spatial heterogeneity in transmission [15]
When Rₜ > 1, epidemic growth is expected, while Rₜ < 1 indicates declining transmission. Accurate estimation of Rₜ is therefore crucial for assessing intervention effectiveness and predicting future case trajectories [15] [21].
Methodological Approaches for R Estimation
Table 2: Methods for Estimating Reproductive Numbers from Epidemiological and Genetic Data
| Method Category | Data Requirements | Software/Tools | Advantages | Limitations |
|---|---|---|---|---|
| Incidence-based | Case counts, serial interval distribution | EpiEstim, custom Bayesian models | Intuitive, rapid computation | Sensitive to case ascertainment, reporting delays [15] |
| Wastewater-based | SARS-CoV-2 RNA concentrations in wastewater | Percent change, GLM models | Unbiased by clinical testing availability; early outbreak detection [16] | Requires calibration with case data; sewershed population definition [16] |
| Phylodynamic | Pathogen genomes, sampling dates | BEAST, BDMM | Incorporates evolutionary history; estimates historical dynamics [22] [17] | Computational intensity; requires sufficient sequence data [20] |
| Spatiotemporal | Georeferenced case data, serial interval | Bayesian model selection/averaging | Captures local heterogeneity; identifies spatial hotspots [15] | Complex implementation; requires fine-scale data [15] |
Protocol: Bayesian Estimation of Rₜ from Case Data
Principle: This approach estimates the time-varying effective reproduction number using case incidence data and the serial interval distribution within a Bayesian framework, allowing incorporation of prior knowledge and quantification of uncertainty [15] [21].
Materials:
- Time-stamped case incidence data
- Serial interval distribution estimates (mean and standard deviation)
- Statistical software (R, Python) with appropriate packages
Procedure:
Data Preparation
- Compile daily or weekly case counts, ensuring consistent reporting periods
- Obtain serial interval distribution from literature or prior studies
- For tuberculosis in Iran, mean serial interval = 1 year was used [21]
- Adjust for reporting delays and back-projection if necessary
Model Specification
- Choose likelihood model: Poisson distribution for case counts
- Specify prior distributions for parameters:
- Rₜ ~ Gamma(mean = 1, SD = 0.5) for mildly informative prior
- Accounting for uncertainty in serial interval estimates
- Select sliding window size for Rₜ estimation (typically 5-14 days depending on reporting frequency)
Implementation
- Code model in Bayesian framework (Stan, PyMC, or use specialized packages like EpiEstim)
- Run Markov Chain Monte Carlo (MCMC) sampling:
- Minimum 10,000 iterations after burn-in of 2,000
- Multiple chains to assess convergence
- For respiratory pathogens with limited data, consider Bayesian model averaging to account for serial interval uncertainty [15]
Output and Interpretation
- Extract posterior median and credible intervals for Rₜ
- Identify time points when Rₜ crosses the epidemic threshold (Rₜ = 1)
- Correlate changes in Rₜ with intervention timing
- Validate model fit using posterior predictive checks
Application Note: In a study of pulmonary tuberculosis in Iran (2018-2022), this approach estimated Rₜ = 1.06 ± 0.05, indicating persistent transmission with each case causing approximately one new infection over time [21].
Integrated Phylodynamic Framework
Protocol: Combined Estimation of Nₑ and R using Pathogen Genomes
Principle: This integrated approach simultaneously estimates effective population size and reproductive numbers from pathogen genomic sequences within a Bayesian phylodynamic framework, leveraging the relationship between genetic diversity and epidemic growth [17].
Figure 1: Workflow for Integrated Phylodynamic Analysis of Nₑ and R
Materials:
- Pathogen whole genome sequences with sampling dates
- Computational resources for Bayesian phylogenetic inference
- Phylodynamic software (BEAST, BEAST2 with appropriate packages)
Procedure:
Data Preparation
- Perform multiple sequence alignment (MAFFT, MUSCLE)
- Assess temporal signal using root-to-tip regression (TempEST)
- Curate metadata: sampling dates, locations if available
Substitution Model Selection
- Test nucleotide substitution models (HKY, GTR) with and without gamma distributed rate heterogeneity
- Use model selection tools (jModelTest, bModelTest) [20]
- Select best-fitting model based on marginal likelihood estimation
Clock Model and Tree Prior Specification
- Choose molecular clock model (strict vs. relaxed clock)
- For epidemics, uncorrelated lognormal relaxed clock often appropriate
- Select tree prior based on epidemic context:
- For integrated analysis, birth-death skyline models can estimate both parameters
MCMC Configuration and Execution
- Configure MCMC chain length (typically 10⁷-10⁹ steps depending on dataset size)
- Set appropriate sampling frequency (every 10,000 steps)
- Specify log parameters (trees, Nₑ, R)
- Run multiple independent replicates to assess convergence
Analysis and Diagnostics
- Assess MCMC convergence (ESS > 200 for all parameters)
- Combine replicates using LogCombiner
- Summarize parameter estimates using Tracer [20]
- Annotate maximum clade credibility tree using TreeAnnotator
Application Example: In a study of West Nile Virus spread in North America, this phylodynamic approach revealed a mean lineage dispersal velocity of ~1200 km/year, with higher dispersal velocities during the early expansion phase of the epidemic [17]. The analysis further identified temperature as a significant environmental predictor of viral genetic diversity through time.
Research Reagent Solutions
Table 3: Essential Research Tools and Resources for Bayesian Phylodynamic Analysis
| Tool/Resource | Application | Key Features | Implementation Considerations |
|---|---|---|---|
| BEAST/BEAST2 | Bayesian evolutionary analysis | Comprehensive model selection; phylodynamics; coalescent inference | Steep learning curve; computational intensity [20] |
| NeEstimator2 | Effective population size estimation | LD-based methods; user-friendly interface; confidence intervals | Limited to contemporary Nₑ; sample size constraints [14] [18] |
| PHLASH | Historical population size inference | Non-parametric estimation; uncertainty quantification; GPU acceleration | New method; requires whole-genome data [19] |
| EpiEstim | Reproduction number estimation | Time-varying Rₜ; simple implementation; rapid results | Sensitive to serial interval specification [15] |
| BDMM | Multi-population transmission dynamics | Structured birth-death model; species transition rates | Complex setup; appropriate for structured populations [22] |
| Tracer | MCMC diagnostics | Parameter convergence assessment; ESS calculation; model comparison | Essential for all Bayesian analyses [20] |
Bayesian phylodynamic methods provide a powerful framework for simultaneously estimating effective population size and reproductive numbers from pathogen genomic data. The protocols outlined here offer researchers standardized approaches for deriving these key evolutionary parameters, with applications ranging from real-time epidemic monitoring to historical reconstruction of outbreak dynamics.
As methodological advancements continue, emerging approaches like PHLASH for population size history inference [19] and wastewater-based reproductive number estimation [16] are expanding the toolkit available to researchers. By following these standardized protocols and selecting appropriate methods based on research questions and data availability, scientists can generate robust estimates of these fundamental parameters to inform public health decision-making and drug development strategies.
The integration of genomic and epidemiological data within a Bayesian framework remains a rapidly evolving field, with ongoing developments in modeling complexity, computational efficiency, and incorporation of additional data sources promising to further enhance the accuracy and utility of these approaches for epidemic research.
Bayesian phylodynamic analysis has become an indispensable tool for reconstructing the evolutionary and transmission history of viral epidemics, providing critical insights into pathogen spread, intervention effectiveness, and emergence of variants. The reliability of these sophisticated statistical models is fundamentally constrained by the quality, completeness, and strategic collection of the underlying data. The integration of genetic sequence alignments with precisely structured metadata forms the empirical foundation upon which all subsequent phylogenetic inferences are built. Furthermore, the temporal and spatial distribution of samples directly determines the analytical resolution achievable in reconstructing epidemic dynamics. This protocol outlines the essential data requirements, preparation methodologies, and sampling strategies necessary for conducting robust Bayesian phylodynamic analyses focused on epidemic spread, providing researchers with a structured framework for generating phylogenetically informative datasets.
Data Types and Requirements
Phylodynamic investigations rely on the synergistic integration of genetic sequence data and associated contextual information. Each data type contributes distinct but complementary information to the analysis.
Genetic Sequence Alignments
Genetic sequence alignments represent the core molecular data for phylogenetic inference, providing the character matrices that record evolutionary changes across lineages.
- Sequence Acquisition: Viral genome sequences are typically generated through high-throughput sequencing technologies from clinical samples. The portability and rapid deployment of modern sequencers enable near real-time generation of complete genome data, which is crucial for outbreak investigation [23].
- Alignment Generation: Raw sequences are aligned against a reference genome or to each other using multiple sequence alignment algorithms (e.g., MAFFT, MUSCLE) to establish positional homology across taxa.
- Quality Control: Alignments must be inspected for sequencing errors, recombination, and misalignment, which can introduce artifacts into phylogenetic reconstruction. For SARS-CoV-2, the limited genetic diversity in early pandemic stages presented particular challenges for phylogenetic resolution [24].
- Format Specifications: Standard alignment formats include FASTA, NEXUS, and PhyloXML, which preserve both sequence data and evolutionary model specifications [25].
Essential Metadata
Metadata provides the essential contextual framework for interpreting phylogenetic patterns biologically and epidemiologically. The table below summarizes critical metadata categories and their phylodynamic applications.
Table 1: Essential Metadata Categories for Phylodynamic Analysis
| Metadata Category | Specific Data Fields | Phylodynamic Application | Example Use Case |
|---|---|---|---|
| Temporal | Sample collection date, Time of symptom onset | Molecular clock calibration, Estimation of evolutionary rates and TMRCA | Estimating time of most recent common ancestor (TMRCA) of SARS-CoV-2 lineages [10] |
| Spatial | Geographic coordinates, Country/Region of origin, Location of sampling | Phylogeographic reconstruction of diffusion pathways, Identification of spatial clusters | Mapping global spread of H1N1pdm from Mexico to worldwide locations [24] |
| Epidemiological | Host species, Clinical status, Transmission setting, Exposure history | Characterizing transmission dynamics, Identifying risk factors | Linking SARS-CoV-2 transmission clusters to specific settings or populations [10] |
| Administrative | Sample identifier, Sequencing platform, Data curator, Access restrictions | Data provenance, Access control, Resource management | Managing data sharing and usage rights in public health emergencies [26] |
Descriptive metadata enables discovery and identification of data resources, while structural metadata describes containers and relationships between data elements [26] [27]. Administrative metadata provides critical instructions for data management, including access restrictions and preservation information, which is particularly important for sensitive public health data [26].
Data Integration Challenges
The integration of genetic alignments with metadata presents several technical challenges that require careful consideration:
- Data Harmonization: Inconsistent formatting, missing values, and taxonomic inconsistencies between data sources can compromise analytical integrity. Automated validation pipelines are essential for large-scale analyses.
- Temporal Resolution: Heterogeneous sampling intervals can create biases in molecular clock estimates and reconstruction of population dynamics [23].
- Spatial Granularity: Variation in geographic resolution (e.g., country-level vs. municipal-level) affects the precision of phylogeographic inference and interpretation of spatial spread.
Sampling Strategy Framework
The strategic collection of samples across relevant dimensions fundamentally determines the analytical scope and inferential power of phylodynamic studies.
Temporal Sampling
Temporal distribution of samples directly impacts the accuracy of evolutionary rate estimation and molecular dating:
- Sampling Density: Higher sampling frequency improves resolution of evolutionary rates and population dynamics. During the SARS-CoV-2 pandemic, intensive genomic surveillance enabled near real-time tracking of variant emergence [10].
- Temporal Span: Longer sampling periods allow for more robust estimation of long-term evolutionary trends and seasonality patterns.
- Representativeness: Samples should proportionally represent incidence dynamics rather than being clustered in short time windows, unless targeting specific transmission events.
Spatial Sampling
The geographic distribution of samples constrains the ability to reconstruct spatial dispersal patterns:
- Global Scale: Analyses of international spread require broadly representative sampling across affected regions. The early SARS-CoV-2 pandemic demonstrated how sampling biases toward certain countries limited understanding of initial transmission routes [10].
- Regional Scale: Dense sampling within regions allows identification of local transmission networks and sources of introduction. For example, phylogeographic analysis of H1N1pdm revealed complex patterns of spatial spread within North America following initial emergence in Mexico [24].
- Sampling Bias Correction: Uneven spatial sampling requires explicit modeling through structured coalescent or birth-death models to avoid erroneous conclusions about transmission dynamics [10].
Phylogenetically Informed Sampling
Strategic sampling based on emerging phylogenetic patterns can optimize resource allocation:
- Oversampling of Emerging Lineages: Targeted sequencing of variants with concerning mutations or epidemiological associations enhances monitoring capacity.
- Bridge Sampling: Focusing on geographic or temporal gaps in existing phylogenies can resolve uncertainties in transmission pathways.
- Outlier Sampling: Including phylogenetic outliers helps delineate the full diversity of circulating lineages and identify previously unrecognized introductions.
Table 2: Impact of Sampling Strategies on Phylodynamic Inference
| Sampling Dimension | Inadequate Approach | Optimal Strategy | Impact on Inference |
|---|---|---|---|
| Temporal Distribution | Clustered sampling in short time periods | Proportional to incidence with regular intervals | Accurate evolutionary rate estimation; Precise dating of emergence events |
| Spatial Distribution | Concentrated in accessible locations | Representative across affected regions; Higher density at suspected sources | Reduced bias in reconstructing spatial spread; Identification of source-sink dynamics |
| Phylogenetic Coverage | Random without consideration of genetic diversity | Strategic targeting of divergent lineages and emerging variants | Comprehensive characterization of diversity; Early detection of novel lineages |
| Metadata Completeness | Inconsistent or incomplete metadata | Standardized collection of temporal, spatial and epidemiological data | Enhanced interpretation of phylogenetic patterns; Robust testing of epidemiological hypotheses |
Experimental Protocols
Protocol 1: Data Collection and Metadata Management
Objective: Establish standardized procedures for collection, documentation, and curation of genetic sequences and associated metadata to ensure phylogenetic utility.
Materials:
- Clinical specimens (swabs, serum, tissue)
- RNA/DNA extraction kits
- High-throughput sequencing platform
- Metadata recording forms (electronic preferred)
- Data management system with version control
Procedure:
- Sample Collection:
- Collect clinical specimens using appropriate methods for the target pathogen
- Record essential contextual data at point of collection using standardized forms
- Implement unique identifiers that link specimens to metadata
Laboratory Processing:
- Extract genetic material using validated protocols
- Perform quality control assessment (e.g., spectrophotometry, electrophoresis)
- Prepare sequencing libraries using appropriate enrichment strategies
Metadata Curation:
- Implement a metadata strategy that defines scope, ownership, and standards [28]
- Establish a metadata vocabulary with formal definitions for consistent communication [27]
- Map metadata to track relationships and ensure traceability to original sources [27]
- Automate metadata processes where possible to reduce errors and improve efficiency [27]
Data Integration:
Troubleshooting:
- Incomplete metadata: Implement validation checks requiring essential fields
- Taxonomic inconsistencies: Apply automated name resolution services
- Temporal anomalies: Flag collection dates outside plausible ranges
Protocol 2: Sequence Alignment and Quality Control
Objective: Generate high-quality multiple sequence alignments suitable for phylogenetic analysis through rigorous quality control procedures.
Materials:
- Raw sequence data (FASTQ format)
- Reference genome(s)
- Computing infrastructure with adequate processing capacity
- Alignment software (e.g., MAFFT, MUSCLE)
- Quality assessment tools (e.g., FastQC, trimAl)
Procedure:
- Sequence Preprocessing:
- Quality filtering and adapter trimming of raw reads
- Assembly using reference-based or de novo approaches
- Verification of complete coding regions for protein-coding genes
Multiple Sequence Alignment:
- Select appropriate alignment algorithm based on data type and size
- Execute alignment with optimized parameters
- Visually inspect alignment for obvious errors using visualization tools
Alignment Refinement:
- Trim poorly aligned regions while preserving phylogenetically informative sites
- Verify reading frames for protein-coding sequences
- Mask hypervariable regions prone to alignment ambiguity
Format Conversion:
- Convert alignment to formats compatible with downstream phylogenetic software (NEXUS, PHYLIP)
- Preserve metadata association through sequence identifiers
Validation:
- Assess alignments using phylogenetic likelihood under simple models
- Compare multiple alignment methods for consistency
- Verify that alignment properties match evolutionary expectations
Visualization and Workflow Diagrams
The following diagrams illustrate the key procedural workflows and data relationships in phylodynamic data management and analysis.
Phylodynamic Data Management Workflow
Metadata Integration Framework
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Research Reagents and Computational Tools for Phylodynamic Studies
| Tool Category | Specific Tool/Reagent | Function | Application Note |
|---|---|---|---|
| Sequencing Technology | Illumina NovaSeq, Oxford Nanopore, PacBio | Generation of raw sequence data from specimens | Portable sequencers enable rapid genomic surveillance in outbreak settings [23] |
| Alignment Software | MAFFT, MUSCLE, Clustal Omega | Multiple sequence alignment from raw sequences | Critical for establishing positional homology before phylogenetic inference |
| Metadata Management | Collibra, Data Catalogs, Custom Databases | Organization and curation of contextual metadata | Essential for maintaining data integrity and enabling reproducible research [26] [28] |
| Phylogenetic Software | BEAST, BEAST2, MrBayes | Bayesian phylogenetic inference with molecular clock | Enables joint estimation of evolutionary and population dynamics [10] [24] |
| Visualization Platforms | PhyloScape, Microreact, Nextstrain | Interactive visualization of annotated phylogenies | PhyloScape supports customizable visualization features with flexible metadata annotation [25] |
| Computational Infrastructure | High-performance computing clusters, Cloud computing | Handling computationally intensive Bayesian analyses | BEAGLE library exploits many-core computing for massive datasets [24] |
Bayesian statistical methods have revolutionized the study of pathogen evolution, enabling researchers to reconstruct transmission pathways, estimate evolutionary parameters, and quantify uncertainty from molecular sequence data. This framework integrates prior knowledge with current epidemiological and genetic data to generate posterior distributions of phylogenetic trees and key parameters, providing a powerful approach for phylodynamic analysis during epidemics. The adoption of Markov Chain Monte Carlo (MCMC) algorithms has been instrumental in making these computationally intensive methods accessible for practical research applications in infectious disease dynamics [29]. This protocol outlines the fundamental concepts, experimental workflows, and analytical tools for implementing Bayesian phylogenetic inference in pathogen evolution research.
Conceptual Foundations of Bayesian Phylogenetics
Bayesian inference in phylogenetics operates on the principle of Bayes' theorem, which calculates the posterior probability of a phylogenetic tree (the hypothesis) given the observed molecular sequence data [29]. The theorem is expressed as:
P(Tree | Data) = [P(Data | Tree) × P(Tree)] / P(Data)
Where:
- P(Tree | Data) is the posterior probability - the probability that the tree is correct given the data, prior, and model
- P(Data | Tree) is the likelihood - the probability of observing the data given a specific tree and evolutionary model
- P(Tree) is the prior probability - represents previous knowledge or assumptions about the tree before analyzing the data
- P(Data) is the marginal probability of the data - often computationally intractable but constant across trees [30]
This framework allows for coherent integration of uncertainty in parameter estimation, making it particularly valuable for complex evolutionary models where multiple explanations may be consistent with the data. The frequencies of trees in the posterior sample have a clear statistical interpretation as probabilities, unlike bootstrap support values from maximum likelihood analyses [30].
Table 1: Comparison of Phylogenetic Inference Frameworks
| Feature | Bayesian Inference | Maximum Likelihood |
|---|---|---|
| Statistical Basis | Inverse probability (Bayes' theorem) | Optimality criterion |
| Output | Sample of trees with posterior probabilities | Single best tree with bootstrap supports |
| Uncertainty Quantification | Direct probability statements | Frequency under data resampling |
| Prior Information | Explicitly incorporated | Not incorporated |
| Computational Approach | Markov Chain Monte Carlo (MCMC) | Heuristic search algorithms |
| Interpretation of Support | Probability tree is correct given data | Frequency branch is found in resampled data |
Key Methodological Components
Markov Chain Monte Carlo (MCMC) Sampling
Since calculating the posterior distribution analytically is computationally prohibitive for phylogenetic problems, Bayesian inference relies on MCMC sampling to approximate the posterior distribution of trees [30]. The Metropolis-Hastings algorithm, a common MCMC approach, follows these steps:
- An initial tree, Ti, is randomly selected
- A neighbor tree, Tj, is selected from the collection of trees
- The ratio R of the probabilities of Tj and Ti is computed: R = f(Tj)/f(Ti)
- If R ≥ 1, Tj is accepted as the current tree
- If R < 1, Tj is accepted as the current tree with probability R, otherwise Ti is kept
- The process repeats for thousands or millions of iterations [29]
This algorithm ensures that the Markov chain eventually reaches a stationary distribution that approximates the true posterior distribution. The Metropolis-coupled MCMC (MC³) variant runs multiple chains in parallel with different "temperatures" to improve mixing and help chains escape local optima in complex tree spaces [29].
Substitution Models and Priors
Selecting appropriate substitution models is critical for accurate phylogenetic inference. For nucleotide sequences, models range from simple (JC69) to complex (GTR+Γ), with the General Time Reversible model with Gamma-distributed rate variation among sites (GTR+Γ) often providing a good balance of complexity and biological realism [20]. Programs like jModelTest and PartitionFinder can assist in model selection, though it is generally better to over-specify than under-specify models in Bayesian phylogenetics [20].
Prior distributions must be specified for all model parameters, including tree topology, branch lengths, and substitution parameters. Common choices include:
- Uniform priors on topologies
- Exponential or gamma distributions on branch lengths
- Dirichlet priors on substitution rates
- Proper priors should be chosen to ensure model identifiability [20]
Application Protocol: Transmission Tree Reconstruction
Experimental Workflow
The following protocol outlines the application of Bayesian inference for reconstructing pathogen transmission trees during outbreaks, integrating genetic and epidemiological data [31].
Figure 1: Bayesian workflow for pathogen transmission inference
Step-by-Step Procedure
Step 1: Data Collection and Preparation
- Obtain whole-genome sequences of the pathogen from infected individuals/premises
- Collect associated epidemiological data:
- Align sequences using appropriate multiple sequence alignment software
- Assess data quality and check for recombination
Step 2: Model Specification
- Select appropriate substitution model (e.g., GTR+Γ) using model testing software
- Specify clock model to relate genetic divergence to time (strict vs. relaxed clocks)
- Define prior distributions for parameters:
- For transmission tree inference, incorporate epidemiological parameters such as generation time distribution and infectious period
Step 3: MCMC Implementation and Diagnostics
- Configure MCMC parameters:
- Chain length (typically millions of generations)
- Sampling frequency (every 1000-10000 generations)
- Number of parallel chains (at least 2, typically 4)
- Heating parameters for MC³ if used [29]
- Monitor convergence using:
- Effective sample sizes (ESS > 200 for all parameters)
- Potential scale reduction factors (≈1.0)
- Trace plots showing good mixing
- If convergence criteria not met, increase chain length or adjust proposal mechanisms
Step 4: Posterior Analysis
- Combine post-burn-in samples from multiple runs
- Summarize tree samples using maximum clade credibility trees
- Calculate posterior probabilities for specific transmission pairs or phylogenetic clusters
- Estimate key parameters: reproductive numbers, mutation rates, transmission distances [31]
- Identify presence of unsampled populations based on unexpectedly long branch lengths [31]
Step 5: Interpretation and Validation
- Annotate trees with epidemiological metadata for visualization
- Compare inferred transmission patterns with independent epidemiological observations
- Assess robustness through sensitivity analyses (different priors, models)
- Estimate the contribution of different transmission routes using structured contact data when available [32]
Table 2: Key Parameters in Bayesian Phylodynamic Inference
| Parameter | Description | Typical Prior | Epidemiological Interpretation |
|---|---|---|---|
| R0 (Basic Reproduction Number) | Average number of secondary cases | Gamma(2,1) | Transmission potential |
| Mutation Rate | Substitutions per site per year | Lognormal(empirical mean) | Evolutionary rate |
| Clock Rate | Molecular evolutionary rate | Lognormal or Gamma | Rate of genetic change |
| Population Size | Effective number of infections | Coalescent priors | Genetic diversity |
| Transmission Rate | Between-host transmission probability | Beta(1,1) | Infectivity |
| Migration Rate | Between-population transmission | Exponential(1) | Spatial spread |
Advanced Applications in Pathogen Phylogeography
Structured Coalescent Framework
For pathogens spreading across multiple geographic locations, the structured coalescent model provides a framework for inferring migration rates and effective population sizes in different locations [33]. The method models how the geographical structure affects genetic similarity, with genomes from the same location being more similar on average than those from different locations.
Implementation Protocol:
- Precompute a dated phylogeny using software such as BEAST, BEAST2, or treedater
- Define the discrete geographic structure (e.g., countries, regions)
- Specify the structured coalescent model with migration rates between locations
- Implement reversible jump MCMC to sample migration histories efficiently
- Estimate location-specific effective population sizes and directed migration rates [33]
Quantifying Transmission Routes
Recent extensions incorporate structured contact data to quantify the contribution of different transmission routes:
- Extend phylodynamic models (e.g., phybreak) to include data on contact types
- Estimate the fraction of transmission events attributable to different contact types (e.g., shared personnel, veterinary visits, environmental transmission)
- Combine genetic sequences, sampling times, and contact data in a unified Bayesian framework [32]
Table 3: Research Reagent Solutions for Bayesian Phylodynamic Analysis
| Tool/Reagent | Function | Application Context |
|---|---|---|
| BEAST/BEAST2 | Bayesian evolutionary analysis | Divergence dating, phylogeography, species tree estimation |
| MrBayes | Bayesian phylogenetic inference | Estimation of species phylogenies and divergence times |
| StructCoalescent | Phylogeographic inference | Exact structured coalescent analysis on precomputed trees |
| phybreak | Transmission tree inference | Outbreak reconstruction combining genetic and epidemiological data |
| jModelTest/PartitionFinder | Substitution model selection | Identifying best-fit evolutionary models for nucleotide data |
| Tracer | MCMC diagnostics | Assessing convergence, effective sample sizes, parameter estimates |
| MultiTypeTree | Structured coalescent implementation | Joint inference of phylogeny and ancestral locations |
Troubleshooting and Optimization
Common Issues and Solutions:
- Poor MCMC Mixing: Increase chain length; adjust proposal mechanisms; use Metropolis-coupled MCMC (MC³) with heated chains
- Low Effective Sample Sizes: Run longer chains; reparameterize model; adjust operator weights
- Prior Sensitivity: Conduct sensitivity analyses with different prior distributions; use empirical priors when justified
- Model Misspecification: Compare alternative models using Bayes factors or posterior predictive checks
- Computational Limitations: Use BEAGLE library to accelerate likelihood calculations; reduce model complexity; utilize cloud computing
Validation Approaches:
- Simulate datasets under known parameters to assess statistical identifiability
- Compare inferences with independent epidemiological observations
- Use cross-validation approaches when possible
- Conduct posterior predictive simulations to assess model fit [31] [33]
The Bayesian framework provides a powerful, coherent approach for inferring pathogen evolutionary and transmission dynamics from genetic and epidemiological data. When properly implemented with appropriate model checking and validation, it offers unique insights into the processes shaping pathogen populations during epidemics.
Methodological Workflow and Practical Applications in Pathogen Genomic Surveillance
Bayesian phylodynamics has become an indispensable methodology for reconstructing the evolutionary and population dynamics of pathogens directly from genetic sequence data. This approach integrates molecular sequences with epidemiological and temporal data within a statistical framework to infer time-scaled phylogenetic trees, population sizes, and reproductive numbers. For researchers studying epidemic spread, selecting the appropriate software toolkit is crucial for generating robust, actionable insights. This protocol focuses on three powerful software platforms—BEAST 2, BEAST X, and MrBayes—comparing their capabilities, providing structured guidance for their application, and detailing experimental workflows for phylodynamic inference. While MrBayes is a cornerstone Bayesian phylogenetics software, the available search results do not provide specific details on its phylodynamic capabilities; thus, this protocol will focus predominantly on the BEAST ecosystem, where comprehensive phylodynamic model information is available.
The BEAST (Bayesian Evolutionary Analysis by Sampling Trees) platform specializes in Bayesian phylogenetic inference using Markov chain Monte Carlo (MCMC), with a core focus on rooted, time-measured phylogenies [34] [35]. Its success stems from an integrative approach that combines sequence, phenotypic, and epidemiological data along time-scaled trees, making it particularly valuable for analyzing rapidly evolving pathogens [36]. The BEAST project has evolved into two main parallel branches: BEAST 2, a modular, extensible software platform first released in 2014 [34], and the newer BEAST X, which introduces significant advances in flexibility and scalability for evolutionary analysis [36] [37]. These tools collectively enable researchers to address critical questions about the origins, spread, and persistence of viral outbreaks, as demonstrated in studies of Ebola, SARS-CoV-2, and mpox virus lineages [36].
Table 1: Core Software Platforms for Bayesian Phylodynamic Analysis
| Software Platform | Primary Focus | Key Strengths | Model Extensibility |
|---|---|---|---|
| BEAST 2 | Bayesian evolutionary analysis of molecular sequences using MCMC [34] [35] | Modular package architecture, active community, wide model variety [38] [34] | High (via BEAST 2 Package Manager) [38] [34] |
| BEAST X | Phylogenetic, phylogeographic, and phylodynamic inference [36] | Advanced algorithms (HMC), state-of-science models, computational efficiency [36] [37] | Built-in high-end models and scalable inference |
| MrBayes | Bayesian phylogenetic inference [35] | Not specified in search results | Not specified in search results |
BEAST 2 Platform
BEAST 2 is a comprehensive software platform for Bayesian evolutionary analysis, serving as a complete rewrite of the original BEAST 1.x series. Its primary design goals focus on usability, openness, and—crucially—extensibility [34]. The software provides a core framework for phylogenetic inference, which can be significantly expanded through a dedicated package management system. This system allows third-party developers to create additional functionality that users can install directly without requiring new software releases [38] [34]. The core BEAST 2 distribution includes several standalone applications: BEAUti (a graphical user interface for setting up analyses), the BEAST engine (for running MCMC analyses), and post-processing tools including LogAnalyser, LogCombiner, TreeAnnotator, and DensiTree [38] [39].
A key innovation in BEAST 2 is its ability to model extended phylogenetic structures beyond classic binary rooted time trees. These include:
- Population and transmission trees where branches represent entire populations and branching events represent population splits or transmission events [38]
- Sampled ancestors where fossils may be direct ancestors of other fossils or extant species [38]
- Structured populations where branches are annotated according to which population the individual belongs to [38]
- Species networks that account for hybridization or admixture events after isolation [38]
BEAST X Advancements
BEAST X represents the latest advancement in the BEAST software lineage, introducing substantial improvements in flexibility and scalability for evolutionary analysis, with a strong focus on pathogen genomics [36] [37]. This version incorporates two major thematic advances: (1) state-of-science, high-dimensional models spanning multiple biological and public health domains, and (2) novel computational algorithms and statistical sampling techniques that dramatically accelerate inference across complex, highly structured models [36].
A significant technical innovation in BEAST X is the implementation of Hamiltonian Monte Carlo (HMC) transition kernels, which leverage linear-time gradient algorithms to efficiently sample from high-dimensional parameter spaces that were previously computationally prohibitive [36] [37]. As shown in Table 1, these advancements yield substantial performance improvements, with effective sample size (ESS) speedups ranging from 5x to 400x compared to conventional Metropolis-Hastings samplers in previous BEAST versions [37].
Table 2: Performance Enhancements in BEAST X via HMC Sampling
| Model Type | Number of Taxa | ESS Speedup |
|---|---|---|
| Birth-death model [37] | 274 | 277x |
| Substitution model [37] | 583 | 15x |
| Molecular clock [37] | 352 | 16x |
| Continuous trait [37] | 3,649 | 400x |
| Discrete trait [37] | 1,531 | 34x |
Model Capabilities Comparison
The BEAST platforms support a wide range of evolutionary models that are essential for phylodynamic inference. These include substitution models for sequence evolution, clock models for rate variation, tree priors for population dynamics, and trait evolution models for phylogeographic analysis.
Table 3: Comparative Model Support Across Platforms
| Model Category | BEAST 2 | BEAST X |
|---|---|---|
| Substitution Models | Standard CTMC models; extendable via packages (e.g., bModelTest) [38] | Markov-modulated models (MMMs), random-effects substitution models [36] [37] |
| Clock Models | Strict, relaxed clocks [34] | Time-dependent rates, continuous random-effects, mixed-effects, shrinkage-based local clocks [36] |
| Tree Priors | Coalescent (Skyline, Skyride, Skygrid), Birth-Death [35] | Enhanced nonparametric coalescent, episodic birth-death sampling [36] |
| Trait Evolution | Discrete and continuous phylogeography [34] | Enhanced discrete/continuous traits, Gaussian trait models, missing-trait models [36] |
| Computational Engine | Standard MCMC, Metropolis-Hastings [34] | Hamiltonian Monte Carlo (HMC), preorder tree traversal [36] [37] |
Experimental Protocols
Core Phylodynamic Analysis Workflow in BEAST
The standard workflow for conducting a phylodynamic analysis using BEAST software involves multiple steps, from data preparation through result interpretation. The following diagram illustrates this end-to-end process:
Protocol 1: Setting Up a Basic Analysis in BEAUti
Purpose: To create a properly configured BEAST XML file for phylogenetic and phylodynamic inference.
Materials/Software:
- BEAST 2 or BEAST X installation
- BEAUti utility (included in BEAST distributions)
- Input sequence alignment file (NEXUS, FASTA, or other supported format)
- Sequence metadata (sampling dates, traits, etc.)
Procedure:
- Launch BEAUti and navigate to the "Partitions" tab.
- Import alignment: Use "File > Import Alignment" or drag-and-drop your sequence file into the BEAUti window [39].
- Configure site and clock models:
- For multi-partition data (e.g., coding/non-coding regions, codon positions), ensure appropriate partitioning strategy [39].
- To account for site-specific rate heterogeneity, select "Gamma" site model for rate variation among sites [39].
- For multi-gene datasets or data with different evolutionary histories, unlink substitution and clock models; for single-gene datasets (e.g., mitochondrial genomes), link tree and clock models across partitions [39].
- Specify tree prior in the "Priors" tab:
- Add calibrations (if available):
- For divergence time estimation, specify node calibrations using fossil evidence or other prior knowledge.
- For serially sampled data, ensure sampling dates are properly specified to calibrate the molecular clock.
- Configure MCMC settings in the "MCMC" tab:
- Set chain length appropriate to dataset size (typically 10-100 million generations).
- Specify logging frequency for parameters and trees.
- Enable state file creation for checkpointing using
-save_everyoptions [40].
- Generate XML file using "File > Save".
Protocol 2: Implementing Phylodynamic Models
Purpose: To configure specific phylodynamic models for epidemic parameter estimation.
Materials/Software:
- BEAST XML file from Protocol 1
- Phylodynamics package (for BEAST 2) [41]
- BEAST X with built-in phylodynamic models [36]
Procedure for BDSIR Model in BEAST 2:
- Install phylodynamics package via BEAST 2 Package Manager [41].
- Open base XML in text editor or BEAUti.
- Replace standard tree prior with Birth-Death SIR (BDSIR) model configuration.
- Set epidemic parameters including R0 (basic reproduction number), recovery rate, and sampling proportions.
- Configure initial conditions for susceptible, infected, and recovered compartments.
- Validate model specification and run analysis.
Procedure for Advanced Phylodynamics in BEAST X:
- Utilize enhanced clock models such as time-dependent evolutionary rate models [36].
- Implement random-effects substitution models to capture non-reversible substitution processes [37].
- Apply HMC sampling for improved efficiency by specifying appropriate transition kernels in the XML.
- Configure missing data models for incomplete trait data using integrated approaches [36].
Protocol 3: Online Bayesian Phylodynamic Inference
Purpose: To incorporate newly available sequences into an ongoing analysis without restarting.
Materials/Software:
- BEAST v1.10.4 or later with checkpointing capability [40]
- Previously generated state/checkpoint file
- New sequence data in aligned format
Procedure:
- Generate state files during analysis:
- Update checkpoint with new sequences:
- Resume analysis with updated checkpoint:
- Example:
beast -load_state updated.checkpoint.state -save_every 20000 -save_state updated.state epiWeekX2.xml[40].
- Example:
Essential Research Reagents and Computational Materials
Successful phylodynamic analysis requires both biological data and computational resources. The following table details key "research reagent solutions" essential for conducting these analyses.
Table 4: Essential Research Reagents and Computational Materials
| Item | Specifications | Function/Purpose |
|---|---|---|
| Molecular Sequence Data | Nucleotide or amino acid sequences in NEXUS, FASTA, or PHYLIP format | Primary data for phylogenetic reconstruction and evolutionary inference |
| Temporal Data | Sampling dates for tip calibration (in years, months, or precise dates) | Enables estimation of evolutionary rates and time-scales phylogenetic trees |
| Trait Data | Discrete (e.g., location, host) or continuous (e.g., virulence) traits | Enables phylogeographic reconstruction and trait evolution analysis |
| BEAST XML File | Configuration file specifying data, models, and MCMC settings | Defines the complete statistical model and analysis parameters for BEAST |
| BEAGLE Library | High-performance computational library, optional GPU support | Accelerates likelihood calculations, essential for large datasets [35] |
| Java Runtime | Version 8 or higher | Required execution environment for BEAST software |
| Post-processing Tools | Tracer, TreeAnnotator, FigTree, DensiTree [39] | Diagnostic checking, tree summarization, and visualization of results |
Troubleshooting and Optimization Guidelines
Assessing MCMC Convergence
A critical step in Bayesian phylogenetic analysis is verifying that the MCMC algorithm has properly converged to the target posterior distribution. Effective Sample Size (ESS) values should be examined for all parameters using Tracer software [35] [39]. ESS values below 100-200 indicate poor mixing and potentially unreliable inferences [35]. Key parameters to monitor include the prior, likelihood, tree likelihood, and all model parameters. If ESS values remain low despite long run times:
- Adjust operator weights in the BEAST XML to improve parameter space exploration
- Increase chain length substantially, particularly for large datasets
- Utilize BEAST X's HMC samplers which can provide substantial efficiency improvements for challenging model parameterizations [36]
Computational Performance Optimization
Phylodynamic analyses can be computationally intensive, particularly with large datasets. Several strategies can improve performance:
- Enable BEAGLE library: This high-performance computational library can significantly accelerate likelihood calculations, particularly when using compatible GPUs for large alignments (>500 unique site patterns) [35].
- Utilize checkpointing: The
-save_everyand-save_statearguments allow analyses to be resumed after interruptions and facilitate model modifications without restarting [40]. - Leverage BEAST X for complex models: When using random-effects substitution models, Markov-modulated models, or high-dimensional trait evolution models, BEAST X's HMC samplers can provide order-of-magnitude efficiency improvements [37].
- Adjust logging frequencies: Reduce memory and storage requirements by increasing intervals between state logging for large analyses.
The BEAST software ecosystem provides a powerful, flexible toolkit for Bayesian phylodynamic inference with direct application to epidemic research. BEAST 2 offers a mature, extensible platform with a rich collection of models via its package system, while BEAST X introduces cutting-edge computational methods and model formulations that significantly advance the scale and complexity of analyses that can be performed. By following the protocols outlined in this document—from basic analysis setup through advanced phylodynamic model implementation—researchers can leverage these tools to uncover critical insights into pathogen evolution, spread, and dynamics. The integration of online inference capabilities further enhances the utility of these platforms for real-time epidemic monitoring, where new sequence data continuously becomes available. As phylodynamic methods continue to evolve, the BEAST platform's extensible architecture ensures it will remain at the forefront of methodological developments in this rapidly advancing field.
Substitution models, also known as models of sequence evolution, are Markov models that describe how molecular sequences, such as DNA or proteins, change over evolutionary time. These mathematical models form the foundation of modern phylogenetic analysis, enabling researchers to estimate evolutionary relationships, divergence times, and population dynamics from molecular sequence data [42]. In Bayesian phylodynamic analyses of epidemic spread, selecting an appropriate substitution model is crucial for accurately reconstructing transmission dynamics, estimating evolutionary rates, and identifying factors driving pathogen evolution [10] [43].
Substitution models operate on the principle that sequences can be represented as strings of discrete states (nucleotides for DNA, amino acids for proteins) that undergo stochastic changes along the branches of phylogenetic trees. The core component of these models is the instantaneous rate matrix (Q matrix), which defines the relative rates at which different character states replace one another during evolution [44] [42]. The general form of this matrix for nucleotide sequences is:
[ Q = \begin{pmatrix} -\muA & \mu{AG} & \mu{AC} & \mu{AT} \ \mu{GA} & -\muG & \mu{GC} & \mu{GT} \ \mu{CA} & \mu{CG} & -\muC & \mu{CT} \ \mu{TA} & \mu{TG} & \mu{TC} & -\muT \end{pmatrix} ]
where (\mu_{xy}) represents the instantaneous rate of change from state (x) to state (y), and the diagonal elements are set such that each row sums to zero [44]. The probability of change from one state to another over a branch length (t) is calculated using matrix exponentiation: (P(t) = e^{Qt}) [42].
The Evolution of Nucleotide Substitution Models
Historical Development from JC69 to GTR
Nucleotide substitution models have evolved from simple symmetrical models to increasingly complex parameter-rich models that better capture the nuances of molecular evolution. The table below summarizes the key characteristics of major nucleotide substitution models:
Table 1: Characteristics of Major Nucleotide Substitution Models
| Model | Year | Parameters | Key Features | Rate Matrix Structure |
|---|---|---|---|---|
| JC69 [45] | 1969 | 0 | Equal substitution rates, equal base frequencies | Single rate λ for all changes |
| K80/K2P [45] | 1980 | 1 | Distinguishes transitions (α) vs. transversions (β) | Different rates for transitions and transversions |
| F81 [45] | 1981 | 3 | Equal rates but unequal base frequencies | Rates proportional to equilibrium frequencies |
| HKY85 [45] | 1984-85 | 4 | Combines K80 with unequal base frequencies | Transition/transversion ratio + frequency parameters |
| TN93 [45] | 1993 | 5 | Distinguishes purine and pyrimidine transitions | Different rates for TC/AG and CT/GA transitions |
| GTR [45] [42] | 1986 | 8 | Most general time-reversible model | Six rate parameters + base frequency parameters |
The JC69 (Jukes-Cantor) model represents the simplest substitution model, assuming equal frequencies of all four nucleotides and equal rates of change between them [45] [46]. The K80 (Kimura 2-parameter) model introduced a biologically important distinction between transitions (changes between purines AG or between pyrimidines CT) and transversions (changes between purines and pyrimidines), with transitions typically occurring at higher rates [45].
The F81 model incorporated unequal equilibrium base frequencies but maintained equal substitution rates between nucleotides [45]. The HKY85 model combined the features of K80 and F81, accounting for both transition-transversion bias and unequal base frequencies, making it one of the most widely used models in contemporary phylogenetic analyses [45] [46].
The TN93 model further refined transition rates by allowing different rates for transitions within pyrimidines (CT) and within purines (AG) [45]. Finally, the GTR (General Time Reversible) model represents the most general time-reversible model, incorporating six different substitution rate categories along with base frequency parameters [45] [42] [46].
Extensions to Basic Models
Several extensions to these basic models have been developed to better capture biological reality. The +Γ extension incorporates rate variation across sites, typically modeled using a discrete gamma distribution [46]. The +I parameter accounts for the proportion of invariant sites, and +F uses empirical base frequencies from the data [46].
More recently, random-effects substitution models have been developed that extend standard continuous-time Markov chain models by incorporating additional rate variation as random effects, enabling more flexible characterization of underlying substitution processes while retaining the basic structure of biologically motivated base models [36]. These models are particularly valuable for capturing non-reversible patterns of evolution, such as the strongly increased rate of C→T substitutions compared to T→C substitutions observed in SARS-CoV-2 [36].
Model Selection Protocols and Implementation
Model Selection Workflow
The selection of an appropriate substitution model is a critical step in phylogenetic analysis. The following protocol outlines a standardized workflow for model selection:
Table 2: Protocol for Substitution Model Selection in Phylodynamic Analyses
| Step | Procedure | Tools | Output |
|---|---|---|---|
| 1. Data Preparation | Align sequences; check for quality and compositional bias | MAFFT, MUSCLE, IQ-TREE | Multiple sequence alignment |
| 2. Initial Tree Estimation | Calculate neighbor-joining tree or rapid maximum likelihood tree | IQ-TREE, RAxML | Starting tree topology |
| 3. Model Selection | Compare models using information criteria (AIC, BIC) or performance-based methods | ModelFinder (IQ-TREE), jModelTest, PartitionFinder | Best-fitting model specification |
| 4. Model Validation | Check model adequacy using posterior predictive simulations | BEAST X, R packages | Assessment of model fit |
| 5. Phylodynamic Analysis | Implement Bayesian inference with selected model | BEAST X, MrBayes | Time-scaled trees, population parameters |
The workflow begins with data preparation, where sequences are aligned and checked for quality. For nucleotide data, it's essential to verify that sequences don't exhibit strong compositional bias that might violate model assumptions. Next, an initial tree is estimated to provide a topological framework for model comparison.
The core of the process is model selection, where multiple models are compared using statistical criteria. The ModelFinder algorithm implemented in IQ-TREE provides an efficient approach that evaluates models based on the Bayesian Information Criterion (BIC), Akaike Information Criterion (AIC), or corrected AIC (AICc) [46]. For Bayesian analyses, Bayes factors can also be used to compare models.
After selecting a model, model validation is crucial to assess whether the chosen model adequately describes the patterns in the data. Posterior predictive simulation, available in software such as BEAST X, can be used to compare observed patterns in the data to patterns simulated under the chosen model [36].
Finally, the selected model is implemented in phylodynamic analysis, where it contributes to estimating time-scaled phylogenies, evolutionary rates, and population dynamics.
Advanced Model Selection Considerations
For complex datasets, particularly those with multiple genetic regions or partitions, partitioned model selection should be performed. This approach allows different regions of the genome to evolve under different substitution processes, which more accurately reflects biological reality [46].
Additionally, model selection for protein-coding genes requires special consideration. While nucleotide models can be applied to protein-coding sequences, codon models that describe substitution between codons rather than nucleotides may be more appropriate as they directly incorporate the structure of the genetic code and selective constraints [42].
Recent advances in random-effects substitution models provide an alternative to traditional model selection by incorporating flexibility directly into the model structure. These models include both fixed effects (the base substitution model) and random effects that capture additional variation, with shrinkage priors pulling random effects toward zero when the data provide little information to the contrary [36].
Table 3: Essential Computational Tools for Substitution Modeling and Phylodynamic Analysis
| Tool/Resource | Function | Application Context |
|---|---|---|
| IQ-TREE [46] | Model selection, fast ML phylogenetics | General phylogenetic inference, model testing |
| BEAST X [36] | Bayesian phylogenetic inference | Phylodynamics, molecular dating, trait evolution |
| ModelFinder [46] | Automated model selection | Identifying best-fit substitution models |
| BEAGLE library [36] | High-performance computation | Accelerating likelihood calculations |
| GISAID [10] [43] | Genomic data repository | Pathogen genome sharing (e.g., SARS-CoV-2) |
| Lie Markov Models [46] | Non-reversible substitution models | Analyzing sequences with non-stationary patterns |
Application in Epidemic Research: SARS-CoV-2 Case Study
The critical importance of appropriate substitution model selection is exemplified in research on the SARS-CoV-2 pandemic. During the first year of the pandemic, nearly 400,000 SARS-CoV-2 genomes were generated and shared publicly, enabling unprecedented tracking of viral spread and evolution [10].
In one foundational study, researchers analyzed 112 SARS-CoV-2 genomes sampled between December 2019 and February 2020 to estimate the time to the most recent common ancestor (TMRCA) and evolutionary rate of the virus [43]. Through careful model comparison and selection, they estimated the TMRCA to be November 12, 2019 (95% BCI: October 11, 2019 - December 9, 2019) and the evolutionary rate to be (9.90 \times 10^{-4}) substitutions per site per year (95% BCI: (6.29 \times 10^{-4} - 1.35 \times 10^{-3})) [43].
Phylodynamic analyses incorporating discrete trait phylogeographic models have been instrumental in tracking the international spread of SARS-CoV-2. These approaches have revealed how the virus initially spread from China to Europe and North America, with subsequent dissemination patterns shifting as travel restrictions were implemented [10]. For example, a study of 427 genomes from Brazil estimated at least 104 international introductions during March and April 2020, predominantly of European origin [10].
The selection of appropriate substitution models has proven particularly important for identifying and characterizing emerging variants. The GTR model with gamma-distributed rate variation has been widely employed for SARS-CoV-2 analyses, though random-effects extensions have provided additional insights into non-reversible substitution patterns, such as the elevated C→T mutation rate observed in this virus [36].
Advanced Methodologies: Random-Effects Extensions and Computational Innovations
Random-Effects Substitution Models
Random-effects substitution models represent a significant advancement beyond standard fixed-effects models. These models extend common continuous-time Markov chain models into a richer class of processes capable of capturing a wider variety of substitution dynamics [36]. Formally, they can be represented as:
[ Q{ij} = Q{ij}^{(base)} + \epsilon_{ij} ]
where (Q{ij}^{(base)}) represents the base substitution rate from the fixed-effects model, and (\epsilon{ij}) represents the random effect that captures additional variation.
These models are particularly valuable when analyzing pathogens like SARS-CoV-2 that exhibit strong non-reversible substitution patterns. In one analysis of 583 SARS-CoV-2 sequences, an HKY model with random effects exhibited strong signals of non-reversibility in the substitution process, with posterior predictive model checks confirming it as a more adequate model than a reversible model [36].
Markov-Modulated Models (MMMs)
Markov-modulated models constitute a class of mixture models that allow the substitution process to change across each branch and for each site independently within an alignment [36]. These models are composed of K substitution models of dimension S that construct a KS × KS instantaneous rate matrix used in calculating the observed sequence data likelihood.
MMMs have been shown to substantially improve model fit compared with standard CTMC substitution models and impact phylogenetic tree estimation in examples from bacterial, viral, and plastid genome evolution [36]. The computational challenges associated with these high-dimensional models are mitigated through recent developments in high-performance computational libraries like BEAGLE [36].
Computational Innovations in BEAST X
The BEAST X software platform introduces several innovations that enhance substitution model implementation in Bayesian phylodynamic analyses:
Hamiltonian Monte Carlo (HMC) sampling: Enables efficient exploration of high-dimensional parameter spaces, particularly for random-effects models [36].
Linear-time gradient algorithms: Allow for scalable computation of likelihood gradients, making complex models applicable to larger datasets [36].
Preorder tree traversal algorithms: Complement postorder algorithms to calculate partial likelihoods and sufficient statistics efficiently [36].
These computational advances have dramatically improved the feasibility of implementing complex substitution models for large genomic datasets, such as those generated during the SARS-CoV-2 pandemic.
Experimental Protocols for Model Selection and Validation
Protocol 1: Standardized Model Selection Using IQ-TREE
Purpose: To systematically identify the best-fitting substitution model for a given DNA sequence alignment.
Materials:
- Multiple sequence alignment in FASTA, PHYLIP, or NEXUS format
- IQ-TREE software (version 1.6 or higher)
- Computational resources (minimum 8GB RAM for typical datasets)
Procedure:
- Prepare your sequence alignment and verify format compatibility.
- Run ModelFinder with the command:
iqtree -s alignment.fa -m MFP - Include rate heterogeneity considerations:
iqtree -s alignment.fa -m MFP+G - For partitioned data:
iqtree -s alignment.fa -m MFP -q partition.txt - Examine the output file
alignment.fa.iqtreefor model selection results. - Identify the model with the lowest BIC score as the best-fitting model.
Validation:
- Check convergence of likelihood scores across model comparisons
- Verify that parameter estimates under the selected model are biologically plausible
- Conduct posterior predictive simulations if using Bayesian framework
Protocol 2: Bayesian Model Comparison Using BEAST X
Purpose: To compare substitution models in a Bayesian framework using marginal likelihood estimation.
Materials:
- BEAST X software package
- Sequence alignment and XML configuration files
- Computational resources appropriate for dataset size
Procedure:
- Prepare XML configuration files for each candidate substitution model.
- Run path sampling/stepping stone sampling for marginal likelihood estimation:
- Calculate Bayes factors between models: (BF = 2(\ln ML1 - \ln ML2))
- Interpret Bayes factors according to standard thresholds (e.g., BF > 10 indicates strong support).
Validation:
- Ensure effective sample sizes (ESS) for all parameters > 200
- Check consistency across multiple independent runs
- Verify that prior choices do not unduly influence marginal likelihood estimates
Substitution model selection has evolved from simple empirical choices to sophisticated statistical procedures that are integral to robust phylodynamic inference. The progression from JC69 to GTR+Γ and now to random-effects extensions represents an ongoing effort to develop models that more accurately capture the complexities of molecular evolution while remaining computationally tractable.
In epidemic research, appropriate model selection is not merely a statistical formality but a fundamental requirement for generating reliable insights into transmission dynamics, evolutionary rates, and spread patterns. The SARS-CoV-2 pandemic has demonstrated both the value of well-specified substitution models and the need for continued methodological development to address emerging challenges.
Future directions in substitution modeling include the development of more efficient computational methods for handling ultra-large datasets, improved integration of epidemiological and evolutionary processes, and enhanced model selection procedures that automatically adapt complexity to the information content in the data. As these advancements mature, they will further strengthen the foundation for phylodynamic inference in epidemic research and public health decision-making.
The molecular clock hypothesis, which proposes that substitutions in nucleotide or amino acid sequences accumulate at a relatively constant rate over time, has become a fundamental tool for understanding the timescale of evolution [47]. This hypothesis, born from the pioneering work of Zuckerkandl and Pauling in the 1960s, allows researchers to estimate divergence times between biological lineages by comparing molecular sequences [47]. However, the assumption of rate constancy is often violated in real biological data, leading to the development of more sophisticated models that can accommodate rate variation across lineages. For researchers studying epidemic spread, accurately modeling the temporal dynamics of pathogens is crucial for reconstructing transmission histories, estimating emergence dates, and understanding population dynamics.
The field has experienced a flourishing of methodological developments, particularly over the last 25 years since the implementation of the first model of rate evolution based on the Bayesian statistical framework [47]. These developments are especially relevant in phylodynamics, which combines phylogenetic analysis with population dynamics to reconstruct the demographic history of populations and the temporal spread of pathogens. In the context of a broader thesis on Bayesian phylodynamic analysis for epidemic research, understanding the nuances of different molecular clock models becomes essential for selecting appropriate methodologies that can accurately reconstruct the evolutionary history and spread of infectious diseases.
Theoretical Foundations of Molecular Clock Models
The Strict Molecular Clock Model
The strict molecular clock model represents the simplest approach to modeling evolutionary rates. Under this model, the substitution rate is assumed to be constant across all branches of the phylogenetic tree, meaning that the genetic distance between sequences is directly proportional to their time of divergence [47] [48]. This model operates on the principle that substitutions follow a Poisson process, where both the mean and variance of the distribution equal the product of rate and time [47]. The index of dispersion (the ratio between mean and variance) should approach unity under a constant rate of evolution, indicating that the observed substitution rate is consistent with a strict molecular clock.
The strict clock can be superior for trees with shallow roots where rate variation between branches is expected to be low [48]. Simulation studies have shown that strict clock analyses perform well when the standard deviation of log rate on branches (σ) is low (σ ≤ 0.1), but become inappropriate when σ > 0.1 [48]. For a mean rate of 0.01 substitutions/site/million years, when σ = 0.1, 95% of rates fall within 0.0082-0.0121 substitutions/site/million years [48]. The strict clock generally provides narrower posterior intervals on divergence times compared to relaxed clock models, making it preferable when rate variation is minimal [48].
Relaxed Molecular Clock Models
Relaxed molecular clock models address the limitation of the strict clock by allowing substitution rates to vary across different branches of the phylogenetic tree. These models are essential when analyzing datasets that exhibit significant rate heterogeneity, which is common in many biological systems, including rapidly evolving pathogens [47]. There are two primary types of relaxed clock models: the independent rates model and the correlated rates model.
The independent rates model assigns a rate to each branch from a single lognormal distribution, with the mean rate and the variance of the log-transformed rate (σ²) typically drawn from gamma distributions specified by the user [48]. Under this model, implemented in programs such as MCMCTREE and BEAST, rates on different branches are independent of each other, allowing for substantial rate variation across the tree [48]. This model performs well across various levels of rate variation, though it produces significantly wider posterior intervals on times compared to the strict clock, particularly when rate variation is high [48].
The correlated rates model incorporates dependency between ancestral and descendant lineages, with rates on branches being correlated with the rate on the ancestral branch [47] [48]. In this model, the mean of the normal distribution for log rate is obtained from the log of the rate on the ancestral branch, and the variance is the product of the branch time duration and a parameter ν specified from a gamma distribution [48]. This approach assumes that descendant lineages inherit rates from their ancestral lineage, with these rates subsequently changing throughout the evolution of newly formed descendant lineages [47]. The correlated rates model is more parameter-rich but also more restrictive than the independent rates model [48].
Time-Dependent Models and Bayesian Model Averaging
Recent advancements in molecular clock modeling have introduced more sophisticated approaches, including time-dependent models and Bayesian Model Averaging (BMA) frameworks. The BMA framework integrates multiple parametric coalescent models—including constant, exponential, logistic, and Gompertz growth—along with their "expansion" variants that account for non-zero ancestral populations [49]. Implemented in a Bayesian setting with Metropolis-coupled MCMC, this approach allows the sampler to switch among candidate growth functions, capturing demographic histories without pre-specifying a single model [49].
This unified BMA framework reduces the need for restrictive model selection procedures and can provide deeper biological insights into epidemic spread and tumor evolution [49]. For epidemic research, this is particularly valuable as it allows researchers to accommodate uncertainty in demographic models when reconstructing the population history of pathogens from genetic data.
Quantitative Comparison of Molecular Clock Models
Table 1: Performance Characteristics of Molecular Clock Models Under Different Levels of Rate Variation
| Model Type | Rate Variation (σ) | Coverage Probability | Posterior Interval Width | Suitable Applications |
|---|---|---|---|---|
| Strict Clock | σ ≤ 0.1 | High (all nodes recovered) | Narrow | Shallow phylogenies with low rate variation |
| Strict Clock | σ > 0.1 | Poor | Inappropriately narrow | Not recommended |
| Independent Rates Relaxed Clock | All σ levels | High (96-100% of nodes recovered) | Significantly wider, especially at high σ | General use, high rate variation |
| Correlated Rates Relaxed Clock | σ > 0.2 | Lower than independent rates model | Intermediate between strict and independent rates | When ancestral-descendant rate correlation is expected |
Table 2: Natural Levels of Rate Variation in Published Datasets and Model Performance
| Dataset | Rate Variation (σ²) | Difference in Divergence Times (Relaxed vs. Strict) | Recommended Model |
|---|---|---|---|
| Black bass | 0.05 | Minimal | Strict Clock |
| Primate-sucking lice | 0.15 | Moderate | Relaxed Clock |
| Podarcis lizards | 0.45 | Significant | Relaxed Clock |
| Gallotiinae lizards | 1.20 | Substantial | Relaxed Clock |
| Caprinae mammals | 3.38 | Very substantial | Relaxed Clock |
Application Protocols for Epidemic Research
Protocol 1: Model Selection and Testing for Pathogen Datasets
Objective: To select an appropriate molecular clock model for analyzing the evolutionary dynamics of pathogens in epidemic spread research.
Materials:
- Multiple sequence alignment of pathogen genomes
- Phylogenetic software (e.g., BEAST, MCMCTREE)
- Calibration information (e.g., sampling dates, known divergence points)
Procedure:
- Perform Likelihood Ratio Test (LRT):
- Calculate likelihoods for trees with and without branch rate constraints
- Compute test statistic: 2 × (lnLunconstrained - lnLconstrained)
- Compare to χ² distribution with (n-2) degrees of freedom, where n is number of taxa
- Note: LRT has low power for σ = 0.01-0.1, but high power for σ = 0.5-2.0 [48]
Estimate Rate Variation Parameter:
- Run preliminary analysis under relaxed clock model
- Examine posterior mean of σ²
- Use guideline: σ² > 0.1 suggests need for relaxed clock [48]
Assess Model Fit:
- Compare marginal likelihoods using stepping-stone sampling or path sampling
- Calculate Bayes factors for model comparison
- Consider using Bayesian Model Averaging if no single model is strongly favored [49]
Validate with Posterior Predictive Simulations:
- Simulate datasets using estimated parameters
- Compare summary statistics of real and simulated data
- Check for adequate model fit to key features of the data
Interpretation: The LRT allows robust assessment of the suitability of the clock model, as does examination of posteriors on σ² [48]. For epidemic research, where accurate estimation of emergence times is crucial, selecting an appropriate clock model can be as significant as the calibration information itself [47].
Protocol 2: Implementing Bayesian Model Averaging for Phylodynamic Inference
Objective: To implement a Bayesian Model Averaging framework for phylodynamic inference without pre-specifying a single demographic model.
Materials:
- Genetic sequences with sampling dates
- Bayesian phylogenetic software with BMA capability
- Computational resources for Metropolis-coupled MCMC
Procedure:
- Specify Candidate Models:
- Include constant, exponential, logistic, and Gompertz growth models
- Add "expansion" variants accounting for non-zero ancestral populations [49]
- Set prior probabilities for each model (typically equal priors)
Configure MCMC Sampling:
- Implement Metropolis-coupled MCMC (MC³) with appropriate number of chains
- For logistic and Gompertz models, use specialized sampling strategies such as adaptive multivariate proposals to achieve robust mixing [49]
- Incorporate correlated-move operators to improve mixing
Run Analysis:
- Execute extended MCMC runs to ensure convergence
- Monitor model switching frequency to ensure adequate exploration of model space
- Assess convergence using effective sample sizes (ESS > 200 for key parameters)
Interpret Results:
- Calculate posterior model probabilities to identify well-supported models
- Examine parameter estimates across models
- Generate model-averaged estimates of key parameters such as population growth rates and divergence times
Application to Epidemic Research: Analysis of Egyptian Hepatitis C virus (HCV) sequences using this approach indicates that models with a founder population followed by a rapid expansion are well supported, with a slight preference for Gompertz-like expansions [49]. Similarly, analysis of metastatic colorectal cancer single-cell datasets suggests that exponential-like growth is plausible even for advanced-stage cancer patients, indicating that tumor subclones may retain substantial proliferative capacity into later disease stages [49].
Visualization of Molecular Clock Methodologies
Figure 1: Decision workflow for selecting appropriate molecular clock models in phylogenetic analysis, showing pathways from sequence data to phylodynamic inference.
Figure 2: Conceptual relationships between different rate evolution models, showing how each model handles rate variation across lineages.
Research Reagent Solutions for Molecular Clock Analysis
Table 3: Essential Computational Tools for Molecular Clock Analysis in Phylodynamics
| Software/Tool | Primary Function | Key Features | Implementation |
|---|---|---|---|
| BEAST2 | Bayesian evolutionary analysis | Implements strict, relaxed clocks; model testing | Independent rates relaxed clock; path sampling |
| MCMCTREE | Bayesian dating with relaxed clocks | Correlated and independent rates models | Approximate likelihood; efficient for large datasets |
| MULTIDIVTIME | Bayesian dating analysis | Correlated rates model | Posterior time estimation with rate autocorrelation |
| BMA Framework | Bayesian model averaging | Integrates multiple coalescent models | MC³ with model switching; logistic/Gompertz growth |
Molecular clock models have evolved significantly from the initial concept of a constant rate of evolution to sophisticated models that accommodate various patterns of rate variation across lineages. For researchers focused on Bayesian phylodynamic analysis of epidemic spread, understanding these models is crucial for accurately reconstructing the temporal dynamics of pathogens. The strict clock model remains appropriate for shallow phylogenies with low rate variation, while relaxed clock models (both independent and correlated rates) are essential for datasets exhibiting significant rate heterogeneity. The recent development of Bayesian Model Averaging frameworks provides a powerful approach for accommodating uncertainty in demographic models, potentially offering deeper biological insights into epidemic spread without the need for restrictive model selection procedures. As the field continues to advance in the era of big data, these methodological improvements will enhance our ability to reconstruct population histories and understand the dynamics of infectious diseases across diverse biological domains.
Phylogeographic analysis has become a cornerstone of modern genomic epidemiology, enabling researchers to reconstruct the spatial dissemination of pathogens by leveraging genetic sequence data. Within the broader framework of Bayesian phylodynamic analysis, these methods uncover the imprint that spatial epidemiological processes leave in the genomes of fast-evolving viruses [50]. The central premise is that epidemic processes, such as viral population growth and geographic subdivision, leave a measurable imprint on pathogen genomes over epidemiological timescales [50]. These approaches were critically applied during the COVID-19 pandemic to track the international spread of SARS-CoV-2 and to investigate the impact of control measures like international travel restrictions [51].
Phylogeographic diffusion can be conceptualized as a process of trait evolution, where geographic location is treated as an inherited property of the virus [50]. The aim is to estimate ancestral locations at internal nodes of a phylogenetic tree conditional on the observed locations of sampled viral sequences. Two principal methodological paradigms exist for this reconstruction: discrete and continuous phylogeographic models. The choice between them depends on the research question, the nature of the sampling scheme, and the scale of the spatial process under investigation [50].
Theoretical Foundations
Discrete Phylogeographic Models
Discrete phylogeographic inference is applicable when viral sequences are available for a limited number of defined locations, such as specific countries, cities, or host species [50]. In this framework, spatial diffusion is typically modeled using a Continuous-Time Markov Chain (CTMC) process, which describes the instantaneous rates of transition between discrete geographic states [50] [52].
A key advancement in Bayesian discrete phylogeography is the integration of Bayesian Stochastic Search Variable Selection (BSSVS), which allows the statistical procedure to focus on a limited set of well-supported migration pathways. This is achieved by allowing transition rates between locations to shrink to zero with some probability, effectively simplifying the model [50]. The support for specific dispersal routes can then be evaluated using Bayes Factor (BF) testing, which compares the posterior to the prior odds that a particular transition rate is non-zero [50]. This method has been applied to investigate the cross-species dynamics of rabies virus in North American bats and the spatial spread of swine influenza viruses [52] [53].
Continuous Phylogeographic Models
Continuous phylogeographic models treat spatial location as a continuously valued trait, with latitude and longitude coordinates evolving along the branches of a phylogenetic tree according to a stochastic process, most commonly Brownian motion [50]. This approach allows ancestral viruses to be placed at any point in a continuous geographical landscape, offering a more realistic representation of spatial history, particularly when samples are distributed across a landscape without strong discrete boundaries [50].
Extensions to the basic Brownian motion model permit diffusion rates to vary through time according to different underlying rate change processes, relaxing the constant variance assumption [50]. However, the assumption of homogeneous diffusion may be more tenable for wildlife or plant viruses in natural landscapes than for human pathogens, which are often dispersed within complex, far-ranging host mobility networks [50].
Comparative Framework
The table below summarizes the core characteristics of discrete and continuous phylogeographic models.
Table 1: Comparison of Discrete and Continuous Phylogeographic Models
| Feature | Discrete Phylogeography | Continuous Phylogeography |
|---|---|---|
| Spatial Representation | Defined set of discrete locations (e.g., countries, host species) | Continuous latitude and longitude coordinates |
| Underlying Model | Continuous-Time Markov Chain (CTMC) | Brownian Motion (or relaxed variants) |
| Ancestral State Reconstruction | Ancestral locations drawn from the set of sampled locations | Ancestral locations can be anywhere in the landscape |
| Key Parameters | Instantaneous rates of transition between locations | Diffusion rate (variance of the Brownian process) |
| Ideal Application | Investigating movement between well-defined regions or compartments | Reconstructing spread across a continuous landscape or where political boundaries are less relevant |
| Visualization | State-proportional trees, flow diagrams | Animated lineages in Google Earth or GIS software [50] |
Application Notes: Protocol for Discrete Phylogeographic Analysis
This protocol provides a methodology for reconstructing spatial dispersal and host-jumping dynamics of pathogens, based on a tutorial for analyzing rabies virus (RABV) in North American bats [52].
Software and Data Requirements
- Software: BEAST (v10.5.0 or later), BEAUti, Tracer (v1.7.2 or later), FigTree (v1.4.4 or later), SPREAD4 [52].
- Computational Library: BEAGLE to accelerate computation [52].
- Input Data:
- A multiple sequence alignment in FASTA format (e.g.,
batRABV.fas). - A tab-delimited trait file associating each sequence with its geographic location and/or host (e.g.,
batRABV_hostLocation.txt).
- A multiple sequence alignment in FASTA format (e.g.,
Step-by-Step Workflow in BEAUti
Loading Data: In BEAUti, import the sequence alignment file via
File > Import Data.... The sequence data will be listed under thePartitionstab [52].Specifying Tip Dates: Switch to the
Tipstab and selectUse tip dates. If sampling dates are encoded in the sequence names, use theParse Datesfunction to extract them automatically. Specify the date format (e.g., years) and ensure the "Height" column correctly reflects the ages of the tips relative to the most recent sample. For sequences with uncertain dates, define a taxon set and apply a flexibleSampling with individual priorsmodel [52].Assigning Traits: Navigate to the
Traitstab andAdd Trait. Import the trait file (batRABV_hostLocation.txt) to associate each sequence with its geographic state and host species. Create a new partition for each trait [52].Setting Evolutionary Models:
- Sites Tab: For the nucleotide partition, select an appropriate substitution model (e.g., HKY) and site heterogeneity model (e.g., Gamma) [52].
- Trait Partitions: For the geographic and host trait partitions, keep the
Symmetric substitution modelbut select the option toInfer social network with BSSVS. This enables model simplification and identification of significant dispersal pathways [52].
Setting the Clock and Tree Models:
Configuring Priors and MCMC: In the
Priorstab, review the default prior distributions. In theMCMCtab, set an appropriate chain length to ensure adequate sampling of the posterior distribution (e.g., 10-100 million steps). Generate the BEAST XML input file [52].
Analysis, Diagnostics, and Visualization
- Run BEAST: Execute the analysis in BEAST using the generated XML file.
- Diagnose Output: Use Tracer to assess MCMC performance, ensure all parameters have effective sample sizes (ESS) > 200, and examine posterior distributions.
- Summarize Trees: Use TreeAnnotator to generate a maximum clade credibility tree from the posterior tree set.
- Visualize Results:
- Use FigTree to visualize the annotated phylogeny.
- Use SPREAD4 or similar software to create visual summaries of the phylogeographic reconstruction, such as estimating the number of transitions between locations and generating KML files for viewing in virtual globe software like Google Earth [50] [52].
The following diagram illustrates the core workflow for this discrete phylogeographic analysis.
Successful phylogeographic analysis relies on a suite of software tools and carefully curated data. The table below lists key components of the research toolkit.
Table 2: Essential Resources for Phylogeographic Analysis
| Resource Name | Type | Primary Function | Key Considerations |
|---|---|---|---|
| BEAST/BEAST2 [52] [54] | Software Package | Core Bayesian phylogenetic inference platform for integrating sequence, temporal, and trait data. | The choice of model (coalescent vs. birth-death) can impact parameter estimates [55] [53]. |
| BEAUti [52] | Utility Software | Graphical user interface for configuring BEAST/BEAST2 analysis parameters and generating XML input files. | Proper configuration of tip dates and trait associations is critical. |
| BEAGLE [52] | Computational Library | High-performance library that accelerates core phylogenetic calculations, enabling analysis of large datasets. | Can leverage GPUs for significant speed improvements. |
| Tracer [52] | Analysis Tool | Diagnoses MCMC output, assesses convergence (ESS), and summarizes parameter posterior distributions. | ESS > 200 is a common threshold for acceptable mixing. |
| FigTree [52] | Visualization Tool | Displays and annotates phylogenetic trees, including node ages and posterior support. | Essential for producing publication-quality tree figures. |
| SPREAD4 [52] | Visualization Tool | Creates visual summaries of phylogeographic reconstructions and generates KML files for Google Earth. | Key for interpreting and presenting spatial diffusion pathways. |
| Time-Stamped Pathogen Genomes | Data | The fundamental input for analysis; genetic sequences with associated collection dates. | Representativeness of sampling across time and space is crucial to avoid bias [53]. |
| Trait Data File [52] | Data | Tab-delimited file linking each sequence to its traits (e.g., geographic location, host). | Data quality and accuracy directly impact reconstruction reliability. |
Integrated Analysis and Emerging Methodological Advances
The true power of Bayesian phylodynamics is realized when phylogenetic information is combined with other data sources to estimate critical epidemic parameters. A significant challenge and area of active development is the joint estimation of effective reproduction number (Re(t)) and prevalence of infection by combining time-stamped genomes with a time series of case counts [54].
Methods like the Timtam package for BEAST2 address this by using an approximate likelihood approach to integrate these data types. This allows researchers to estimate not only the transmission tree of sequenced samples but also the number of "hidden lineages" (unsequenced or unobserved infections) through time, which is essential for understanding true prevalence [54]. Such approaches were demonstrated in analyses of SARS-CoV-2 outbreaks on the Diamond Princess cruise ship and the 2010 poliomyelitis outbreak in Tajikistan [54].
The following diagram illustrates the relationship between the complete transmission process, the data collected, and the key parameters estimated in such an integrated framework.
Discrete and continuous phylogeographic models provide a powerful, model-based framework for reconstructing the spatial dynamics of epidemics from pathogen genomic data. The choice between these approaches depends on the research question and the nature of the available spatial data. The integration of these methods into broader Bayesian phylodynamic frameworks, especially when combined with epidemiological time-series data, allows for a more comprehensive understanding of epidemic spread. This includes the estimation of critical parameters like reproduction numbers and infection prevalence, which are indispensable for informing public health and animal disease surveillance strategies [51] [54] [53]. As genomic surveillance becomes more routine, these analytical approaches will continue to be vital for translating genetic data into actionable epidemiological insights.
Bayesian phylodynamic analysis has emerged as a powerful framework for elucidating the transmission dynamics and evolutionary trajectories of rapidly evolving pathogens. This approach integrates molecular sequence data with epidemiological and temporal information within a statistical framework to reconstruct pathogen spread, estimate evolutionary parameters, and inform public health interventions. Unlike traditional phylogenetic methods, Bayesian phylodynamics accounts for uncertainties in evolutionary parameters, including pathogen phylogeny, population demographics, and dispersal history, making it particularly valuable for studying pathogens that evolve on the same timescale as their epidemiological spread [56]. This application note demonstrates how this unified methodological approach provides critical insights for both human and veterinary medicine through case studies of SARS-CoV-2 variants and Porcine Reproductive and Respiratory Syndrome Virus (PRRSV) outbreaks.
The following tables summarize key quantitative data for SARS-CoV-2 variants and PRRSV, highlighting their respective impacts on public health and swine production.
Table 1: Characteristics of Major SARS-CoV-2 Variants of Concern
| Variant (WHO Label) | Key Spike Protein Mutations | Impact on Transmissibility | Impact on Immunity | Impact on Severity |
|---|---|---|---|---|
| Alpha (B.1.1.7) | N501Y, D614G, Δ69-70, P681H | ~50-100% increase compared to original strain | Moderate immune escape | Slightly increased severity |
| Beta (B.1.351) | K417N, E484K, N501Y | ~50% increase compared to original strain | High immune escape | No significant increase observed |
| Delta (B.1.617.2) | L452R, T478K, P681R | Highly increased (up to 2× more than Alpha) | Moderate immune escape | Possible increase in severity |
| Omicron (BA.2.86) | I332V, E484K, F486P, N450D | Extremely high transmissibility | High immune escape | Lower average severity [57] [58] |
Table 2: PRRSV Impact on Swine Production Performance
| Production Parameter | PRRSV Epidemic Lots | Non-Epidemic Lots | Impact Assessment |
|---|---|---|---|
| Nursery Mortality (%) | Significantly higher | Baseline | Substantial negative impact [59] |
| Reproductive Performance (pre-acclimatization) | Suboptimal | Baseline | Reduced farrowing rates |
| Reproductive Performance (post-serum acclimatization) | Significantly improved | N/A | Effective control strategy [60] |
| Seasonal Variation | Higher in winter/spring | Lower in summer/autumn | Clear seasonal pattern [60] |
SARS-CoV-2 Variant Tracking: Protocol and Application
Genomic Surveillance and Variant Classification Framework
The protocol for SARS-CoV-2 variant tracking relies on integrated genomic surveillance systems that monitor the emergence and prevalence of variants through sequencing and phylogenetic analysis. The CDC's National SARS-CoV-2 Strain Surveillance program exemplifies this approach, combining sequences generated from surveillance specimens with those contributed by other laboratories and entered into public databases [61]. Variants are classified based on their genetic sequences and observable characteristics, with three primary categories used to communicate increasing levels of concern: Variants Under Monitoring (VUM), Variants of Interest (VOI), and Variants of Concern (VOC) [58].
The analytical workflow involves several key steps: (1) sample collection from diverse geographical locations and time points; (2) genomic sequencing to obtain complete viral genomes; (3) sequence alignment and quality control; (4) phylogenetic analysis to identify emerging lineages; (5) characterization of mutations in critical regions like the spike protein; and (6) integration of genomic data with epidemiological metrics to assess transmissibility, immune escape potential, and virulence. This process enables researchers to track variant proportions in populations using both empiric estimates based on observed genomic data and nowcast estimates that model-based projections for the most recent periods [61].
Bayesian Phylodynamic Analysis of SARS-CoV-2 Variants
Bayesian phylodynamic methods implemented in software platforms such as BEAST X enable sophisticated inference of SARS-CoV-2 evolutionary and transmission dynamics. The protocol incorporates several advanced modeling approaches:
Substitution Models: Random-effects substitution models extend common continuous-time Markov chain models to capture a wider variety of substitution dynamics, enabling more appropriate characterization of underlying evolutionary processes. These models can identify non-reversible substitution patterns, such as the strongly increased rate of C→T substitutions in SARS-CoV-2 compared to T→C substitutions [36].
Molecular Clock Models: Time-dependent evolutionary rate models accommodate rate variations through time, which is particularly relevant for SARS-CoV-2 with its long-term transmission history in human populations. These models utilize phylogenetic epoch modeling to specify unique substitution processes throughout evolutionary history, with boundaries determining shifts in evolutionary rates that apply to all lineages simultaneously [36].
Discrete-trait Phylogeography: This approach models viral spread between geographical locations using continuous-time Markov chains, with recent advancements addressing geographic sampling bias sensitivity. BEAST X implements novel modeling strategies that parameterize between-location transition rates as log-linear functions of environmental or epidemiological predictors, with Hamiltonian Monte Carlo approaches to handle missing predictor values [36].
Diagram: Bayesian Phylodynamic Workflow for SARS-CoV-2 Variant Analysis
PRRSV Outbreak Investigation: Protocol and Application
Epidemiological Investigation and Causal Inference Analysis
The protocol for investigating PRRSV outbreaks in swine populations involves a comprehensive epidemiological approach that combines field data collection with advanced causal inference methods. A recent study analyzed data from 2,592 lots of pigs, representing approximately 5 million animals, to quantify the impact of sow farm PRRSV outbreaks on downstream nursery mortality [59]. The methodology follows several key stages:
Study Design and Data Collection: Implement a retrospective cohort design where lots of pigs serve as observational units. The exposure variable is defined as the PRRSV epidemic status in source sow farms, with "epidemic" classification applied to the first 16 weeks after a reported outbreak. The outcome variable is nursery mortality, expressed as the percentage of pigs that died during the first 60 days of the post-weaning phase. Data collection should integrate pre-weaning productivity and health information from sow farms with lot closeout performance reports [59].
Causal Diagram Development: Convene a panel of subject matter experts to construct a directed acyclic graph visualizing the relationship between PRRSV epidemic exposure and nursery mortality, while identifying potential confounding factors. The minimum sufficient set of variables for measuring the total effect typically includes season, average parity at farrow, and sow farm Mycoplasma hyopneumoniae status [59].
Statistical Analysis: Employ multiple analytical approaches to estimate the effect of PRRSV on mortality: (1) univariate regression models; (2) multivariable regression models; (3) propensity score matching; and (4) doubly robust estimation. The doubly robust method provides the most accurate estimates with lower mortality differences and narrower confidence intervals, as it combines regression adjustment with propensity score weighting to protect against model misspecification [59].
Bayesian Phylodynamic Analysis of PRRSV Transmission
Bayesian phylodynamic methods provide complementary insights into PRRSV evolution and spread at the molecular level. The protocol for PRRSV phylodynamic analysis includes:
Sequence Data Preparation: Collect ORF5 nucleotide sequences from field isolates with associated metadata including date of isolation, production system code, and farm type. Perform sequence alignment using tools such as MUSCLE and manually adjust using amino-acid translation methods to ensure the protein-coding region remains in frame. Screen for homologous recombination using tools like Recombination Detection Program and select the best-fitting nucleotide substitution model using the Bayesian Information Criterion in PartitionFinder [56].
Phylodynamic Model Specification: Implement coalescent and discrete trait phylodynamic models in Bayesian software such as BEAST X to infer population growth, demographic history, and dispersal routes among production systems. Discrete trait models can identify significant transmission routes with Bayes Factor analysis, while continuous trait models can reconstruct spatial spread when precise geographic data are available [56] [36].
Molecular Epidemiology Applications: Apply phylodynamic inference to identify the most likely ancestral system for outbreaks and quantify viral exchange among systems. Studies have demonstrated that sow farms often serve as hubs for PRRSV spread within production systems, providing critical intelligence for targeted intervention strategies [56].
Diagram: PRRSV Outbreak Investigation and Control Workflow
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Essential Research Reagents and Materials for Phylodynamic Studies
| Item | Specification/Application | Research Function |
|---|---|---|
| Nucleic Acid Extraction Kit | Magnetic bead-based virus DNA/RNA extraction | Isolation of high-quality viral RNA for sequencing [60] |
| RT-qPCR Detection Kit | Target-specific primers and probes (e.g., PRRSV ORF5, SARS-CoV-2 spike) | Pathogen detection and quantification [60] |
| Sequencing Platform | Next-generation sequencing systems | Whole genome sequencing for variant characterization [56] |
| BEAST X Software | Bayesian evolutionary analysis software package | Phylodynamic inference incorporating molecular clock and population dynamics models [36] |
| Sequence Alignment Tool | MUSCLE, MAFFT, or similar algorithms | Multiple sequence alignment for phylogenetic analysis [56] |
| Model Selection Software | PartitionFinder with Bayesian Information Criterion | Selection of best-fitting evolutionary models [56] |
| Positive Control Serum | Quantified virus stock for challenge studies | Serum acclimatization studies and vaccine efficacy testing [60] |
The integrated application of Bayesian phylodynamic methods for both SARS-CoV-2 and PRRSV demonstrates the power of this approach across human and veterinary medicine. While these pathogens affect different hosts and present distinct clinical manifestations, the core analytical framework provides valuable insights into their evolutionary dynamics and transmission patterns. For SARS-CoV-2, phylodynamics has been essential for tracking emerging variants, assessing their phenotypic impacts, and guiding public health responses. For PRRSV, these methods illuminate transmission routes within production systems and inform control strategies such as serum acclimatization. The complementary use of epidemiological causal inference and molecular phylodynamics offers a comprehensive approach to understanding and mitigating infectious disease threats at the human-animal interface. As pathogen surveillance systems continue to generate large-scale genomic data, Bayesian phylodynamic analysis will play an increasingly critical role in translating sequence information into actionable public and animal health intelligence.
Troubleshooting Computational Workflows and Optimizing Model Performance
In Bayesian phylodynamic analysis of epidemic spread, the reliability of posterior estimates for key parameters, such as the basic reproduction number (R₀) or the infectious period, is paramount. Since Markov Chain Monte Carlo (MCMC) methods are the computational backbone for obtaining these posterior distributions, verifying that the MCMC sampling has converged to the true target distribution is a critical step. Phylodynamic models, which unify epidemiological dynamics with phylogenetic trees, are particularly complex, making rigorous convergence diagnostics essential for producing scientifically valid inferences [5]. This protocol details the application of two cornerstone diagnostic methods: the analysis of Effective Sample Size (ESS) and trace plots. The ESS quantifies the amount of independent information in an autocorrelated MCMC sample, while trace analysis visually assesses the stability and mixing of the chains [62] [63]. Together, they form a fundamental toolkit for researchers, scientists, and drug development professionals to validate their computational findings in epidemic research.
Theoretical Background
The Role of MCMC in Bayesian Phylodynamics
Bayesian phylodynamic inference leverages MCMC algorithms to approximate the posterior distribution of model parameters by sampling from a high-dimensional probability space. This space includes not just epidemiological parameters (e.g., transmission rates, recovery rates) but also the phylogenetic tree of the pathogen itself. The MCMC algorithm generates a sequence of correlated samples, and the central limit theorem for Markov chains ensures that summaries from these samples (e.g., the sample mean) converge to the true posterior summaries. However, this guarantee is only asymptotic. In practice, with finite computation time, one must diagnose whether the chain has run long enough to provide a reliable approximation [5] [64].
Effective Sample Size (ESS)
The ESS is a critical diagnostic that measures the efficiency of an MCMC sampler. Unlike a simple sample size, the ESS accounts for the autocorrelation within the MCMC chain. It estimates the number of independent samples that would provide the same level of precision for estimating the posterior mean as the autocorrelated MCMC samples. A low ESS indicates high autocorrelation, meaning the sampler is exploring the parameter space inefficiently and the estimates of posterior means and medians may be unreliable [62] [63].
The conventional formula for ESS is derived under the assumption of homoscedastic outcome data and is given by:
$$ESS = \frac{(\sum{j=1}^{n} \hat{w}j)^2}{\sum{j=1}^{n} \hat{w}^2j}$$
where n is the number of samples and ŵ represents weights [65]. However, newer methodologies are being developed to compute ESS under more general conditions, making it applicable to a wider range of data types, such as survival data common in epidemic modeling [65].
Tracer and Trace Plot Analysis
A "tracer" in the context of MCMC diagnostics refers to a tool or method used to monitor the values of parameters throughout the sampling iterations. The primary visual tool for this is the trace plot, which shows the sampled value of a parameter against the iteration number. A well-mixing chain should, after an initial burn-in period, resemble a "hairy caterpillar," meaning it should be stable around a central value with constant variance and no discernible trends [62].
Diagnosing a chain via trace plots involves assessing:
- Mixing: The chain should rapidly traverse the posterior distribution without getting stuck in one region for long periods.
- Burn-in: The initial portion of the chain that has not yet converged to the typical set of the posterior must be identified and discarded.
- Stationarity: The mean and variance of the chain should remain constant after burn-in.
Essential Diagnostics and Their Interpretation
The following table summarizes the key MCMC diagnostics, their calculation, and how to interpret their values in the context of phylodynamic analysis.
Table 1: Key MCMC Diagnostics for Phylodynamic Analysis
| Diagnostic | Calculation/Method | Interpretation | Target |
|---|---|---|---|
| Effective Sample Size (ESS) | Estimated via coda::effectiveSize() or similar functions [62]. |
Measures information content; low ESS implies high uncertainty in posterior means. | ESS > 200-400 per chain is often recommended [63]. |
| Trace Plot | Visual plot of parameter value vs. MCMC iteration [62] [63]. | Assesses mixing, stationarity, and identifies burn-in. A healthy plot looks like a "hairy caterpillar" [62]. | Stable, well-mixed, trend-free plot after burn-in. |
| Acceptance Rate | Proportion of proposed states accepted by the Metropolis-Hastings algorithm [62]. | Rate that is too low or too high indicates inefficient proposal distribution. | ~0.20-0.40 for single parameters; can be harder to tune for multiple parameters [62]. |
| Autocorrelation Plot | Plot of correlation between samples at different iteration lags [62]. | High, persistent autocorrelation indicates slow mixing and high correlation between samples. | Autocorrelation should drop to zero relatively quickly as lag increases. |
| Gelman-Rubin Diagnostic (R̂) | Compares within-chain and between-chain variance for multiple chains [63]. | R̂ >> 1 indicates chains have not converged to the same distribution. | R̂ ≤ 1.01 is a common convergence threshold [63]. |
Protocol: A Step-by-Step Workflow for MCMC Diagnostics
This protocol provides a detailed workflow for assessing MCMC convergence in a Bayesian phylodynamic analysis, using R and the coda and bayesplot packages.
Research Reagent Solutions
Table 2: Essential Software Tools for MCMC Diagnostics
| Tool Name | Type | Primary Function in Diagnostics |
|---|---|---|
| R Statistical Environment | Programming Language | The primary platform for statistical analysis and running diagnostic functions. |
coda R Package |
Software Library | Provides core functions for calculating ESS, rejection rates, and creating autocorrelation plots [62]. |
bayesplot R Package |
Software Library | Specializes in visual MCMC diagnostics, including trace plots, NUTS-specific diagnostics, and parallel coordinate plots [63]. |
| Phylodynamic Software (e.g., BEAST, MrBayes) | Application | Software that generates the MCMC samples from the phylodynamic model. Output is analyzed using the tools above. |
Detailed Experimental Workflow
The following diagram outlines the core diagnostic workflow.
Step 1: Load MCMC Output and Convert to coda Format
After running your phylodynamic MCMC simulation (e.g., in BEAST), load the posterior samples into R. This often involves reading a tabular file of parameter samples. Convert this data into an mcmc object for use with the coda package.
Step 2: Generate and Interpret Trace and Density Plots Create a combined trace and density plot for all parameters of interest. This is the first and most intuitive diagnostic check.
Interpretation: Look for stability in the trace plot (no pronounced drifts or trends) and a smooth, unimodal density. The initial period where the chain has not stabilized is the burn-in and should be discarded. As noted in the practical guide, a well-mixed chain should look like a "hairy caterpillar" [62].
Step 3: Assess Autocorrelation High autocorrelation reduces the ESS and indicates inefficient sampling.
Interpretation: The autocorrelation should drop to near zero as the lag increases. If autocorrelation remains high, thinning the chain (keeping only every k-th sample) can be considered, though it is more computationally efficient to run a longer chain or improve the model parameterization [62].
Step 4: Calculate and Evaluate the Effective Sample Size (ESS) Compute the ESS for each parameter to ensure you have enough independent samples for reliable inference.
Interpretation: There is no universal minimum ESS, but a common rule of thumb is to have an ESS of at least 200-400 for each parameter of interest. Warnings about low ESS indicate that posterior means and medians may be unreliable and that running the chains for more iterations may be necessary [63].
Step 5: Comprehensive Summary Generate a summary report that includes quantiles and time-series standard errors.
The "Time-series SE" corrects the naive standard error of the mean for autocorrelation and is a more honest measure of estimation uncertainty [62].
Advanced Diagnostics and Troubleshooting
For more complex models, especially those fit using Hamiltonian Monte Carlo (HMC) and its No-U-Turn Sampler (NUTS) variant, additional diagnostics are available via the bayesplot package.
Divergent Transitions in HMC/NUTS: Divergences are a serious warning that the sampler has trouble exploring parts of the posterior. They can often be diagnosed using a parallel coordinates plot or a pairs plot.
Divergences often point to issues with model specification or parameterization, such as regions of high curvature in the posterior [63].
Parameterization: For hierarchical models, a centered parameterization (CP) might lead to sampling inefficiencies or divergences when group-level variances are small. Switching to a non-centered parameterization (NCP) can often resolve these issues [63].
Application in Phylodynamics: An Ebola Virus Example
In a phylodynamic analysis of the 2014 West African Ebola epidemic, MCMC diagnostics are crucial for validating estimates of epidemic spread. For instance, a researcher might be jointly estimating the time to the most recent common ancestor (TMRCA) of viral sequences and the epidemic's basic reproduction number R₀ [5].
The workflow would involve running an MCMC in a phylodynamic software package, then applying the protocol in Section 4. The trace plots for R₀ and the evolutionary rate must show stationarity. The ESS for these parameters should be sufficiently high (e.g., >200) to trust the estimated credible intervals. Furthermore, in analyses that incorporate spatial predictors (e.g., using the seraphim R package), assessing the convergence for the coefficients of these predictors (e.g., distance to roads, chicken density) via ESS and trace analysis is necessary to make robust conclusions about their role as conductance or resistance factors in viral spread [66]. Low ESS for these parameters would suggest the need for a longer MCMC run or a re-parameterization of the model before drawing any scientific inferences.
Robust MCMC diagnostics are non-negotiable in Bayesian phylodynamic research. The integrated use of ESS and tracer analysis provides a powerful means to verify that computational results are reliable reflections of the underlying model and data, rather than artifacts of an incomplete sampling process. By adhering to the detailed protocols and interpretations outlined in this document, researchers in epidemic spread and drug development can ensure the validity and credibility of their findings, leading to better-informed public health and therapeutic interventions.
Bayesian phylodynamic analysis has become an indispensable tool for reconstructing the transmission dynamics of epidemics, as demonstrated during the 2014 West African Ebola outbreak [5]. As researchers model increasingly complex evolutionary and epidemiological processes, they often encounter a fundamental computational barrier: the curse of dimensionality. High-dimensional parameter spaces, characterized by numerous free parameters, present significant challenges for Bayesian inference through Hamiltonian Monte Carlo (HMC) sampling [67]. This application note provides a structured framework for diagnosing and resolving HMC convergence issues within high-dimensional phylodynamic analyses, offering practical protocols to enhance computational efficiency and inference reliability for epidemic spread research.
Computational Challenges in High-Dimensional Spaces
The Curse of Dimensionality in Phylodynamics
High-dimensional parameter spaces, domains with numerous free parameters, exhibit exponential volume growth that rapidly renders brute-force sampling approaches intractable [67]. In phylodynamics, dimensionality increases with complex models incorporating multiple evolutionary rates, population parameters, and migration rates. The mathematical properties of these spaces are dominated by concentration-of-measure phenomena, where Lipschitz-continuous functions concentrate sharply near their mean, making exploration of the posterior distribution exceptionally challenging [67].
HMC-Specific Limitations in Multimodal Distributions
While HMC generally offers superior scaling properties in high-dimensional spaces compared to other MCMC algorithms, it encounters particular difficulties with strongly multimodal target distributions [68]. These challenges manifest as Markov chains with infrequent transitions between modes, potentially leading to incomplete exploration of the posterior and biased representation of the target distribution [68]. Depending on initialization, chains may become trapped in local modes, failing to discover globally dominant regions of high probability.
Diagnostic Framework for HMC Convergence
Key Diagnostic Warnings and Their Interpretation
Stan, a widely used platform for HMC sampling, provides specific warnings that indicate potential problems with sampler performance [69]. The table below summarizes critical diagnostics and their interpretations for phylodynamic applications:
Table 1: HMC Convergence Diagnostics and Interpretations
| Diagnostic | Warning Sign | Interpretation | Practical Implication |
|---|---|---|---|
| Divergent Transitions | >0 transitions after warmup | Incorrect discrete-time approximation of Hamiltonian dynamics; biased estimates [69] | Posterior estimates may not represent true distribution |
| R-hat | >1.01 (final), >1.1 (early workflow) | Chains have not mixed properly; between- and within-chain variance disagree [69] | Insufficient exploration of parameter space; unreliable inferences |
| Bulk- and Tail-ESS | <100×number of chains | Effective sample size too low for accurate estimation of posterior means and quantiles [69] | Posterior summaries have high uncertainty |
| Maximum Treedepth | Frequent warnings | NUTS terminating prematurely to avoid excessive computation time [69] | Inefficient sampling; potentially missed regions of parameter space |
| BFMI | <0.3 | Poor adaptation of mass matrix or thick-tailed posteriors [69] | Inefficient exploration of target distribution |
Diagnostic Workflow Protocol
The following workflow provides a systematic approach to diagnosing HMC convergence issues in phylodynamic analyses:
Diagram 1: HMC Diagnostic Workflow
Protocol 1: Comprehensive HMC Diagnostic Assessment
- Initial Sampling: Run at least four parallel chains with different initial values for a minimum of 1,000 iterations after warmup [69] [70].
- Divergence Check: Examine sampling output for divergent transitions. Even a small number (<10) may indicate biased estimation.
- Convergence Metrics: Calculate R-hat statistics for all parameters. For final inferences, require R-hat < 1.01; for early workflow, R-hat < 1.1 may be acceptable [69].
- Sampling Efficiency: Evaluate bulk- and tail-ESS values. For final results, bulk-ESS should be >100×number of chains [69].
- Algorithm Efficiency: Check for maximum treedepth warnings, which indicate computational inefficiency rather than validity concerns.
- Energy Diagnostics: Verify BFMI > 0.3 to ensure adequate exploration of the target distribution [69].
Mitigation Strategies for High-Dimensional Problems
Addressing Divergent Transitions and Poor Mixing
Protocol 2: Resolution of Geometric Issues
- Reparameterization: Transform parameters to make the posterior distribution more amenable to HMC sampling. For phylogenetic models, this may include using log-transforms for strictly positive parameters or softmax transforms for simplex-constrained parameters.
- Increase adaptdelta: Gradually increase the adaptdelta parameter (e.g., from 0.8 to 0.95 or 0.99) to reduce step size and improve approximation accuracy [69].
- Model Simplification: Identify and eliminate non-identifiable parameters through prior predictive checks. A model is non-identifiable if different parameter values yield identical predictions [20].
- Advanced HMC Variants: Implement tempered HMC methods that use time-varying mass to facilitate transitions between isolated modes in multimodal distributions [68].
Dimensionality Reduction Techniques
Protocol 3: Managing High-Dimensional Parameter Spaces
- Active Subspace Identification: Compute the eigendecomposition of the matrix C = ∫(∇f(x))(∇f(x))ᵀρ(x)dx to identify parameter combinations that dominate system variation [67].
- Parameter Blocking: For state-space models, partition the state-space into locally interacting blocks such that filtering and smoothing recursions are performed within neighborhoods rather than globally [67].
- Surrogate Modeling: Employ Gaussian process regression or artificial neural networks as surrogate models to approximate the likelihood function, dramatically reducing computational requirements [71].
- Manifold Learning: Apply techniques such as diffusion maps to extract intrinsic low-dimensional structure from high-dimensional parameter spaces [67].
Advanced Sampling Approaches
Tempered HMC for Multimodal Distributions
For strongly multimodal target distributions common in complex phylodynamic models, standard HMC may fail to transition between modes. Automatically-tuned, tempered HMC (ATHMC) addresses this by simulating Hamiltonian dynamics with time-varying mass, enabling efficient exploration of isolated modes [68].
Protocol 4: Implementation of Tempered HMC
- Mass Modulation: Configure a schedule where mass gradually increases during the first half of the simulation path, providing energy to traverse low-probability regions between modes.
- Mode Settlement: Gradually decrease mass during the second half of the simulation, allowing the sampler to settle in alternative modes.
- Automatic Tuning: Implement automatic tuning of temperature parameters to minimize manual configuration requirements [68].
- Validation: Compare posterior estimates with standard HMC to ensure consistency while verifying improved mode exploration.
Neural Network-Enhanced HMC
Recent advances integrate artificial neural networks with HMC to accelerate gradient computations through automatic differentiation [71]. This approach is particularly valuable for high-dimensional reaction kinetics models, with demonstrated efficiency improvements of three to four orders of magnitude over traditional MCMC methods [71].
Phylodynamic Application Framework
Software Solutions for Bayesian Phylogenetics
Table 2: Bayesian Phylogenetic Software for Phylodynamic Analysis
| Software | Primary Application | Strengths | Citation |
|---|---|---|---|
| BEAST | Divergence time estimation, phylodynamics, phylogeography | Vast model library, active development | [20] |
| MrBayes | Species phylogeny estimation | Broad substitution model support, user-friendly | [20] |
| RevBayes | Complex hierarchical models | Flexible model specification language | [20] |
| Stan | General Bayesian inference | Advanced HMC implementation, diagnostics | [69] |
Integrated Workflow for Epidemic Spread Research
The following diagram illustrates the relationship between various mitigation strategies and their applications in phylodynamic analysis:
Diagram 2: Mitigation Strategy Relationships
Protocol 5: Integrated Phylodynamic Analysis Pipeline
- Model Specification: Define phylogenetic model with careful consideration of prior distributions and identifiability constraints [20].
- Pilot Analysis: Conduct short pilot runs to identify potential computational challenges.
- Diagnostic Assessment: Apply Protocol 1 to evaluate sampler performance.
- Targeted Mitigation: Implement appropriate mitigation strategies from Protocols 2-4 based on diagnostic results.
- Validation: Compare posterior estimates across multiple runs and model specifications to ensure robustness.
- Inference: Extract biological insights from converged sampling results, with particular attention to epidemic parameters such as reproduction numbers and migration rates.
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Tool/Reagent | Function | Application Context | Citation |
|---|---|---|---|
| BEAST Software Package | Bayesian evolutionary analysis | Phylogenetic reconstruction, divergence dating, phylodynamics | [20] |
| Stan with HMC Implementation | Advanced Bayesian sampling | High-dimensional inference with improved geometric exploration | [69] |
| Tracer | MCMC diagnostics and summary | Visualization and assessment of chain convergence | [20] |
| Automatic Differentiation | Gradient computation for HMC | Enables efficient sampling in high dimensions | [71] |
| Tempered HMC Algorithms | Multimodal distribution sampling | Isolated mode exploration in complex posteriors | [68] |
| Active Subspace Methods | Dimensionality reduction | Identification of influential parameter combinations | [67] |
Bayesian phylodynamic methods have become indispensable for reconstructing the geographic and demographic history of disease outbreaks, enabling researchers to infer key aspects such as the origin of an epidemic, its dispersal routes, and the number of transmission events [72]. These inferences are performed within a Bayesian statistical framework, where prior probability distributions, reflecting our beliefs about model parameters before seeing the data, are updated by the information in the data to yield posterior distributions [72]. However, inference under discrete-geographic phylodynamic models is inherently sensitive to prior specification because these models involve estimating a large number of parameters from a minimal amount of information—often just a single geographic observation per pathogen sample [72] [73].
This prior sensitivity is a pervasive and concerning feature of empirical studies. The default priors implemented in widely used software like BEAST reflect extremely strong and biologically unrealistic assumptions about the underlying dispersal process [72] [73]. Alarmingly, these defaults have been used in the vast majority (~93%) of published biogeographic studies in BEAST and have been shown to strongly distort central conclusions [73]. Therefore, a rigorous and systematic approach to prior sensitivity analysis is not merely a technical formality but a fundamental requirement for robust and biologically sound phylodynamic inference.
Theoretical Foundations of Prior Specification
The Bayesian Inference Problem
In discrete-geographic phylodynamics, the parameters of interest are typically the instantaneous-rate matrix, Q, which defines the dispersal rates between geographic areas, and the average dispersal rate, μ. The joint posterior probability distribution of these parameters, given the geographic data (G) and a phylogeny (Ψ), is estimated using Bayes' theorem [73]:
[P(\mathbf{Q}, \mu \mid G, \Psi) = \frac{ P(G \mid \mathbf{Q}, \mu, \Psi) P(\mathbf{Q}) P(\mu) }{ P(G) }]
Here, the prior distribution (P(\mathbf{Q}) P(\mu)) is updated by the likelihood function (P(G \mid \mathbf{Q}, \mu, \Psi)). When the data contain limited information, the posterior estimates for parameters can closely resemble the priors, a clear indicator of prior sensitivity [73].
Contrast with Substitution Models
The challenge of prior sensitivity becomes starkly evident when contrasting discrete-geographic models with nucleotide substitution models. A general time-reversible (GTR) substitution model has 4 states (A, C, G, T) and 6 rate parameters, typically inferred from a sequence alignment with hundreds or thousands of sites. In contrast, a discrete-geographic model with k=10 areas has between 45 (symmetric model) and 90 (asymmetric model) parameters. Crucially, these must all be estimated from an "alignment" with a single "site"—the geographic location of each tip in the tree [73]. This combination of many parameters and minimal data is the root cause of inherent prior sensitivity.
Default Priors and Their Pitfalls
A critical default prior in BEAST governs the number of dispersal routes (Δ) in a model. When using Bayesian Stochastic Search Variable Selection (BSSVS), each potential dispersal route is associated with an indicator variable, δ~ij~, which is 1 if the route exists and 0 otherwise. The total number of routes, Δ, is the sum of these indicators.
The default prior on Δ is a Poisson distribution, but its parameterization has strong and often biologically implausible implications [73]. For symmetric models, it is an offset Poisson with ( \lambda = \ln(2) ), placing about 50% of the prior probability on models with the absolute minimum number of dispersal routes. For asymmetric models, the prior has ( \lambda = k - 1 ). This reflects a very strong a priori preference for sparse models with minimal connectivity, an assumption that may not be justified for many pathogens and can adversely distort inferences [73].
A Framework for Prior Sensitivity Analysis
Strategies for Specifying Improved Priors
Researchers have several strategies to navigate prior sensitivity [73]:
- Biologically-Motivated Priors: Incorporating existing knowledge from the literature to focus prior probability on a realistic range of parameter values.
- Diffuse/Uninformative Priors: Spreading prior probability evenly over a wide range of plausible values to minimize prior influence.
- Systematic Assessment: Formally evaluating the impact of a range of candidate priors on posterior estimates.
Alternative Prior Distributions for Dispersal Routes
Moving beyond the default Poisson prior, tools like PrioriTree allow researchers to specify more flexible and appropriate priors on the number of dispersal routes, Δ [73].
Table 1: Alternative Prior Distributions for the Number of Dispersal Routes (Δ)
| Prior Type | Key Parameters | Mathematical Formulation | Interpretation and Use Case |
|---|---|---|---|
| Poisson Prior | Rate parameter (λ) | ( P(\Delta) \sim \text{Poisson}(\lambda) ) (offset for symmetry) [73] | The default in BEAST. Adjusting λ allows control over the expected number of routes. A higher λ creates a more diffuse prior. |
| Beta-Binomial Prior | Shape parameters (α, β) | ( p \sim \text{Beta}(\alpha, \beta) ) ( \Delta \mid p \sim \text{Binomial}(n, p) ) [73] | A highly flexible hierarchical prior. The user can tune α and β so that the resulting Beta-Binomial prior on Δ has a desired mean and 95% interval. |
| Uniform Prior | (A special case of Beta-Binomial) | ( P(\Delta) = \frac{1}{n+1} ) for ( \Delta = 0, 1, ..., n ) [73] | Assumes all possible numbers of dispersal routes (from zero to the maximum) are equally probable a priori. A maximally uninformative choice. |
Experimental Protocols for Sensitivity Analysis
Protocol 1: Robust Bayesian Inference
Robust Bayesian inference assesses the "robustness" of posterior estimates by comparing them across a range of different, biologically plausible prior distributions [72] [74].
Workflow Overview:
Detailed Methodology:
- Define Candidate Priors: Select a set of alternative prior distributions for key parameters (e.g., the average dispersal rate μ or the prior on the number of dispersal routes Δ). For instance, compare the default Poisson prior against a Beta-Binomial prior with a higher expected number of routes and a more diffuse Uniform prior [73] [74].
- Generate Analysis Files: Use PrioriTree to generate a series of BEAST XML input files. Each file should specify an identical model and dataset but a different prior from the candidate set [74].
- Execute MCMC Simulations: Run BEAST for each XML file to perform Markov chain Monte Carlo (MCMC) sampling. Perform multiple, independent replicate runs for each prior-model combination to ensure convergence and adequate sampling [74].
- Import and Process Log Files: Within PrioriTree, upload the BEAST log files containing the parameter estimates. The tool automatically identifies common parameters across logs. Select the focal parameter (e.g., a specific dispersal rate or μ) for sensitivity analysis. Configure post-processing settings, including burn-in proportion and whether to combine replicate log files [74].
- Visualize and Interpret: PrioriTree generates a plot of the marginal posterior probability distributions for the selected parameter under each candidate prior.
- Robust Conclusion: If the posterior distributions are nearly identical across different priors, the inference for that parameter is considered robust to prior choice.
- Prior-Sensitive Conclusion: If the posterior distributions vary substantially and closely resemble their corresponding priors, the parameter is prior-sensitive, and the choice of prior is critical. In this case, a biologically informed prior or a conservative, diffuse prior is strongly recommended [72] [74].
Protocol 2: Data Cloning for Prior Impact Assessment
Data cloning is a powerful method to quantify the relative contribution of the prior and the data to the posterior distribution. It measures how quickly the posterior converges to the maximum likelihood estimate (MLE) as the data's influence is artificially increased [72] [74].
Workflow Overview:
Detailed Methodology:
- Define Priors and Clone Series: Select one or more priors to evaluate. Then, define a series of data-cloning analyses. This involves creating copies ("clones") of the original geographic dataset. A typical series might include β~i~ = 1 (the original data), 5, 10, and 20 clones [74].
- Generate and Execute Analyses: Use PrioriTree to generate the corresponding BEAST XML files for the specified clone numbers. Run BEAST for each of these files [74].
- Summarize and Visualize: Import the resulting log files into PrioriTree. The tool will generate a plot showing the marginal posterior probability distributions for a parameter (e.g., μ) across the different numbers of data clones [72] [74].
- Interpret Results:
- Slow Convergence: If the posterior mean estimates change significantly as the number of clones increases (e.g., from 1 to 5 to 20), it indicates that the specified prior is highly informative and exerts a strong influence on the posterior relative to the data [72].
- Fast Convergence: If the posterior mean estimates remain stable and effectively identical across increasing clone numbers, it indicates that the prior is relatively uninformative and the data dominate the posterior [72].
Table 2: Essential Computational Tools for Prior Sensitivity Analysis in Phylodynamics
| Tool / Resource | Type | Primary Function in Sensitivity Analysis |
|---|---|---|
| BEAST / BEAST 2 [72] [75] | Software Package | Core software platform for performing Bayesian evolutionary and phylodynamic analysis via MCMC. |
| PrioriTree [72] | R Package / Utility | An interactive utility designed specifically for identifying and accommodating prior sensitivity. It generates BEAST input files for robust inference and data cloning, and summarizes output. |
| BEAUti [73] | GUI Application | A graphical user interface for generating BEAST XML input files. Often used in conjunction with PrioriTree. |
| R | Programming Language | The statistical computing environment in which PrioriTree is implemented; also used for custom post-processing and plotting of results. |
| Poisson Prior [73] | Prior Distribution | A prior for the number of dispersal routes. Requires careful specification of the rate parameter (λ) to avoid overly informative defaults. |
| Beta-Binomial Prior [73] | Prior Distribution | A flexible hierarchical prior for the number of dispersal routes, allowing the user to explicitly specify beliefs about its mean and uncertainty. |
Addressing Model Non-Identifiability and Parameter Overparameterization
Model non-identifiability and parameter overparameterization present significant challenges in Bayesian phylodynamic analysis of epidemic spread. Non-identifiability occurs when different combinations of parameter values yield identical model predictions, making it impossible to distinguish between these combinations using the available data [20]. Overparameterization, the use of excessively complex models with too many parameters relative to the informative content of the data, can lead to inflated uncertainties, convergence issues, and computationally inefficient inference [20] [76]. Within the context of epidemic research, these issues can compromise the reliability of key epidemiological parameters such as effective population sizes, reproduction numbers, and migration rates, ultimately affecting public health interventions and drug development strategies.
Bayesian phylodynamic methods have become indispensable tools for reconstructing epidemic dynamics from pathogen genetic sequence data [77] [78]. However, the flexibility of non-parametric models such as the skygrid, skygrowth, and skysigma models, which infer changes in effective population size through time, introduces important model design choices that can affect inference results [79]. Similarly, complex compartmental models integrated within phylogenetic inference frameworks enable estimation of epidemiologically relevant parameters but increase the risk of overparameterization [77]. This application note provides detailed protocols and solutions for identifying and mitigating these issues, ensuring robust phylodynamic inference.
Core Concepts and Definitions
Problem Definitions
- Model Non-Identifiability: A statistical model is non-identifiable if distinct parameter values (θ₁ ≠ θ₂) produce identical likelihoods for all possible data sets (f(D|θ₁) = f(D|θ₂)) [20]. In phylodynamics, a classic example involves the estimation of divergence times (t) and evolutionary rates (r); the likelihood depends only on their product (the genetic distance d = r × t), making it impossible to estimate time and rate separately without additional information [20].
- Parameter Overparameterization: This occurs when a model incorporates more parameters than can be reliably informed by the available data. This leads to high variance in parameter estimates, poor Markov chain Monte Carlo (MCMC) convergence, and a general failure to pinpoint the values of epidemiological parameters of interest [20] [76].
- Complex Coalescent Models: Highly parameterized demographic models like the skygrid involve precision parameters (τ) and numerous population size segments, requiring careful tuning to avoid overfitting [79].
- Mechanistic Epidemiological Models: Compartmental models (e.g., SIR, SEIR) integrated with phylogenetic inference introduce numerous kinetic parameters that may not be well-constrained by genetic data alone [77].
- Molecular Clock Models: Relaxed clock models that assign independent rate parameters to each branch can easily become overparameterized, especially when sequence data lack strong temporal signal [36].
Quantitative Framework and Diagnostic Table
Table 1: Diagnostics and Solutions for Non-Identifiability and Overparameterization
| Problem Type | Diagnostic Indicators | Affected Phylodynamic Parameters | Proposed Solution Protocols |
|---|---|---|---|
| Likelihood Non-Identifiability | Flat likelihood surface; infinite confidence intervals; strong correlation between parameters in MCMC samples [20]. | Divergence time (t) and evolutionary rate (r) [20]; Prevalence and contact rate in SIR models [77]. | Incorporate strong priors (e.g., from fossil data or serology); use data augmentation [20]; model reparameterization [76]. |
| Prior Non-Identifiability | Posterior distribution perfectly mirrors the prior distribution; parameter estimates are insensitive to data [20] [76]. | Precision parameter (τ) in skygrid/skygrowth models [79]; weakly informed parameters in complex GLM phylogeographic models [80]. | Employ cross-validation for tuning (e.g., for τ) [79]; use penalized complexity (PC) priors; conduct prior sensitivity analysis [76]. |
| Overparameterization | Poor MCMC convergence (low ESS); high posterior variance for parameters; poor predictive performance [76]. | Branch-specific rates in uncorrelated relaxed clocks [36]; numerous predictors in phylogeographic GLMs [80]. | Apply Bayesian variable selection (Bayes Factors, BFs); use random-effects models with shrinkage priors [36]; implement model averaging [20]. |
Experimental Protocols for Mitigation
Protocol 1: Cross-Validation for Smoothing Parameter Selection
Objective: To optimize the precision parameter (τ) in non-parametric phylodynamic models (e.g., skygrid) using a frequentist cross-validation approach, mitigating overfitting [79].
- Model Specification: Define a piecewise demographic model (e.g., skygrid, skygrowth, skysigma) with an initial value for the precision parameter τ.
- Data Partitioning: Divide the genealogical data into k distinct subsets of roughly equal size.
- Iterative Training and Prediction:
- For each subset i, treat it as the test set. Train the phylodynamic model on the remaining k-1 subsets, estimating the log population sizes (γ).
- Use the estimated γ from the training set to compute the coalescent likelihood of the test genealogy.
- Score Calculation: Compute the total out-of-sample predictive score across all k folds. This score is typically the sum of the log predictive probabilities for each test set.
- Optimization: Repeat steps 3-4 for a range of candidate τ values. Select the value of τ that maximizes the out-of-sample predictive score.
- Final Inference: Run a final phylodynamic inference on the complete dataset using the optimized τ value.
Protocol 2: Hamiltonian Monte Carlo (HMC) for High-Dimensional Models
Objective: To improve MCMC sampling efficiency and convergence in complex, overparameterized models by leveraging HMC, which uses gradient information for more effective exploration of the posterior [36].
- Model Configuration: Set up a phylodynamic model in a software package that supports HMC (e.g., BEAST X). This is particularly useful for models with many parameters, such as random-effects substitution models, skygrid coalescent models, and mixed-effects clock models.
- Gradient Configuration: Enable the calculation of likelihood gradients. This may involve specifying preorder and postorder tree traversal algorithms for linear-time gradient computations [36].
- HMC Sampler Tuning:
- Set the trajectory length (number of leapfrog steps) and step size. These can often be set to auto-tune during an initial phase of the MCMC run.
- For models with branch-specific parameters (e.g., relaxed clocks), ensure the HMC transition kernel is applied to these parameter blocks.
- MCMC Execution: Run the analysis, monitoring the acceptance rate of the HMC moves. An optimal acceptance rate is typically around 65-80%.
- Diagnostic Checking: Assess convergence by checking Effective Sample Sizes (ESS) for key parameters. HMC should yield higher ESS per unit time compared to traditional Metropolis-Hastings samplers [36].
Protocol 3: Bayesian Variable Selection in Phylogeographic Models
Objective: To identify the most relevant predictors of spatial spread and reduce overparameterization in generalized linear models of phylogeographic transition rates [80].
- Predictor Assembly: Compile a matrix of potential predictors for each location pair (e.g., geographical distance, population sizes, road connectivity, airline traffic) [80].
- Model Specification: Implement a GLM where the log transition rates are a linear function of the predictors. Assign a spike-and-slab prior (or another variable selection prior) to the regression coefficients (β). This prior has a "spike" at zero (representing predictor exclusion) and a "slab" (a diffuse prior for non-zero coefficients).
- MCMC Inference: Perform Bayesian inference, sampling both the model parameters and the inclusion indicators for each predictor.
- Posterior Analysis: Calculate the posterior probability of inclusion for each predictor. A probability >0.5 (or a higher threshold) provides evidence for including the predictor.
- Model Refinement: Refit the phylogeographic model retaining only predictors with strong posterior support, thereby creating a more parsimonious and interpretable model.
Visualization of Workflows
Diagram 1: Protocol Integration Workflow
The diagram below outlines the logical relationship and decision process for selecting the appropriate protocols to address identifiability and overparameterization issues.
The Scientist's Toolkit
Table 2: Essential Research Reagent Solutions for Phylodynamic Inference
| Tool / Reagent | Function / Application | Implementation Notes |
|---|---|---|
| BEAST 2 / BEAST X | Primary software platform for Bayesian phylogenetic and phylodynamic inference, supporting a vast array of evolutionary models [78] [36]. | Essential for integrating sequence evolution, trait evolution, and demographic models. BEAST X offers newer, more scalable inference algorithms like HMC [36]. |
| PhyDyn Package | BEAST 2 package for fitting complex compartmental epidemiological models (e.g., SIR) to genetic data using structured coalescent approximations [77]. | Used for translating ODE-based epidemic models into a phylodynamic framework; critical for estimating R0 and incidence from genetic data. |
| Tracer | Software for diagnosing MCMC performance, assessing convergence via ESS, and summarizing posterior distributions [20] [76]. | Low ESS values for key parameters are a primary indicator of overparameterization or poor identifiability. |
| jModelTest / PartitionFinder | Programs for selecting nucleotide substitution models via statistical criteria (e.g., AIC, BIC) [20]. | Helps prevent overparameterization of the substitution process by selecting a model with appropriate complexity. |
| Cross-Validation Scripts | Custom scripts (e.g., in R or Python) to implement k-fold cross-validation for tuning parameters like the skygrid's τ [79]. | A frequentist approach to optimize smoothing parameters and improve out-of-sample prediction accuracy. |
| Spike-and-Slab Priors | A type of prior distribution used in Bayesian variable selection to determine which predictors to include in a model [80]. | Implemented in BEAST for phylogeographic GLMs to identify significant predictors of spatial spread and reduce overfitting. |
Best Practices for Partitioning Data and Handling Model Complexity
In Bayesian phylodynamic analysis of epidemic spread, the reconciliation of complex molecular data with computationally intensive models is a fundamental challenge. The accuracy of inferences—whether estimating phylogenetic trees, effective population sizes, or reproduction numbers—is contingent upon appropriately specifying the evolutionary model and accounting for heterogeneity in the underlying data [20] [81]. Model misspecification or failure to account for variation in evolutionary patterns across a sequence alignment can lead to biased parameter estimates and incorrect phylogenetic reconstructions [82] [83]. This protocol details best practices for two cornerstone techniques: data partitioning, which aims to model heterogeneous substitution processes across different subsets of the alignment, and strategies for managing model complexity to ensure robust and efficient phylodynamic inference. These methods are particularly vital for analyzing pathogen genomic data to understand the dynamics of epidemic spread, as exemplified in studies of Ebola virus and SARS-CoV-2 [36] [5].
Data Partitioning Strategies
Data partitioning involves estimating independent models of molecular evolution for different groups of sites in a sequence alignment. This accounts for variation in rates of evolution, base frequencies, and substitution patterns, which is crucial for improving model fit and phylogenetic inference [83].
A Priori Partitioning
The simplest partitioning approach defines subsets based on prior knowledge of the data structure.
- Common Schemes: Standard schemes include partitioning by:
- Gene: Assigning different genomic regions to distinct subsets.
- Codon Position: Treating 1st, 2nd, and 3rd codon positions within protein-coding genes separately, as they evolve under different selective constraints.
- Structural Features: Partitioning ribosomal RNA genes into stem and loop regions [82] [20] [83].
- Applications and Limitations: This method is practical for datasets with only a few genes. However, it becomes unwieldy for phylogenomic datasets with hundreds or thousands of loci and may not capture the full heterogeneity within the data [83].
Rate-Based Partitioning with TIGER and RatePartitions
For a more objective approach that uses properties of the data itself, the TIGER (Tree Independent Generation of Evolutionary Rates) method can be used.
- Principle: TIGER calculates a relative evolutionary rate for each site in an alignment by comparing character-state distributions without requiring a tree estimate. Sites are then grouped based on similarity of their relative rates [82].
- The RatePartitions Algorithm: A subsequent Python script, RatePartitions, groups sites into partitions in an objective way. It ensures the distribution of sites across partitions follows the distribution of evolutionary rates in the full dataset. This creates larger partitions for slowly evolving sites and smaller partitions for fast-evolving sites, avoiding the pitfall of placing all invariable sites into a single partition, which can lead to model selection errors [82].
- Protocol:
- Input Preparation: Prepare a sequence alignment in a common phylogenetic format (e.g., FASTA, NEXUS).
- Run TIGER-rates: Execute TIGER-rates on the alignment to generate a file containing the relative evolutionary rate for every site.
- Execute RatePartitions: Run the RatePartitions script, specifying the TIGER-rates output and a desired number of partitions. The script calculates rate-spans for each partition and assigns sites accordingly.
- Output: The script generates a NEXUS-style file defining the character sets for each partition, which can be directly used in downstream phylogenetic software [82].
Hierarchical Clustering for Phylogenomic Datasets
For very large phylogenomic datasets, traditional greedy algorithms for finding optimal partitioning schemes are computationally infeasible. Hierarchical clustering offers a scalable alternative [83].
- Strict Hierarchical Clustering: This algorithm starts with all user-defined data blocks as independent subsets. It then iteratively calculates model parameters and the similarity between all pairs of subsets, combining the two most similar subsets at each step. This process continues until all sites are combined into a single subset. The best partitioning scheme from the resulting hierarchy is selected using a model selection criterion like AICc or BIC [83].
- Relaxed Hierarchical Clustering: This improved method incorporates elements of both strict hierarchical clustering and the greedy algorithm. It explores multiple partitioning schemes within a specified "search radius" at each clustering step, leading to dramatically better results than strict hierarchical clustering while remaining computationally tractable for large datasets [83].
- Workflow: The following diagram illustrates the general workflow for implementing hierarchical clustering partitioning, as implemented in PartitionFinder.
Comparison of Partitioning Methods
Table 1: A comparison of data partitioning methods for phylogenetic inference.
| Method | Principle | Best For | Advantages | Disadvantages |
|---|---|---|---|---|
| A Priori | User-defined subsets based on biological knowledge [83]. | Small datasets with few genes or simple structures. | Intuitive; easy to implement. | Does not capture hidden heterogeneity; becomes unwieldy with many loci. |
| RatePartitions | Partitions sites based on relative evolutionary rates from TIGER [82]. | Single- and multi-gene datasets of small to moderate size. | Objective, data-driven method; avoids model selection pitfalls. | Requires running additional software (TIGER, RatePartitions). |
| Strict Hierarchical Clustering | Iteratively combines most similar subsets based on model parameters [83]. | Very large phylogenomic datasets (computationally efficient). | Highly computationally efficient (O(N) complexity). | Performance is inferior to relaxed hierarchical clustering. |
| Relaxed Hierarchical Clustering | Combines subsets within a search radius at each clustering step [83]. | Very large phylogenomic datasets where computational feasibility is a concern. | Scalable efficiency; returns dramatically better partitioning schemes than strict clustering. | More computationally demanding than strict clustering, but less than greedy algorithms. |
Handling Model Complexity
Selecting an appropriate evolutionary model and managing its parameters is as critical as partitioning the data. Over-parameterization can lead to inefficient computation and loss of power, while under-parameterization can cause biased results [20].
Model Selection and Identifiability
- Substitution Models: For nucleotide data, models range from simple (e.g., JC69) to complex (e.g., GTR+Γ). Tools like
jModelTestandPartitionFindercan help select a model based on criteria like AICc or BIC [20] [83]. As a rule of thumb, it is often less problematic to over-specify than to under-specify the model in Bayesian phylogenetics [20]. - Model Identifiability: A model is non-identifiable if different parameter values make identical predictions about the data, making those parameters impossible to estimate jointly. A classic phylogenetic example is the inability to separately estimate the divergence time (t) and evolutionary rate (r) from a simple two-sequence alignment, as the likelihood depends only on the product ( d = rt ) [20].
- Clock Models: BEAST X includes advanced clock models to handle rate heterogeneity across the tree. These include:
- Uncorrelated Relaxed Clock: Allows rates to vary freely across branches.
- Time-Dependent Evolutionary Rate Model: Accommodates rate variations through time for all lineages (e.g., in rapidly evolving viruses with long transmission histories) [36].
- Shrinkage-Based Local Clock Model: A tractable and interpretable extension of the random local clock model [36].
- Tree and Coalescent Models: For phylodynamic inference, coalescent models like the skygrid model can infer past population dynamics without strong assumptions about population size trends. Structured coalescent models can be used to estimate migration rates between discrete populations (e.g., geographic locations) [36] [84].
Computational Inference Techniques
Advanced computational methods are essential for fitting complex models to large datasets.
- Hamiltonian Monte Carlo (HMC): BEAST X implements HMC transition kernels for many models. HMC uses gradients of the posterior distribution to propose more efficient moves through high-dimensional parameter spaces, leading to much faster convergence and higher effective sample sizes (ESS) per unit time compared to conventional Metropolis-Hastings samplers [36].
- Preorder Tree Traversal Algorithms: These algorithms, combined with postorder traversals, enable the calculation of gradients for branch-specific parameters (e.g., evolutionary rates, divergence times) in time linear to the number of taxa (O(N)). This scalability is a prerequisite for the efficient use of HMC on large phylogenetic trees [36].
Protocol for Managing a Complex Phylodynamic Analysis
The following workflow integrates partitioning and model complexity management into a coherent protocol for a Bayesian phylodynamic analysis in a software environment like BEAST X.
Step-by-Step Procedure:
Data Preparation and Partitioning:
- Compile your sequence alignment and any associated metadata (e.g., sampling dates, locations).
- Determine an optimal partitioning scheme using one of the methods described in Section 2.0 (e.g., using
PartitionFinderwith a hierarchical clustering approach for large datasets) [83].
Model Specification:
- Substitution Model: Apply the best-fit model (e.g., GTR+Γ) to each partition, potentially using a mixture model like Markov-modulated models (MMMs) to capture additional heterogeneity [36].
- Clock Model: Select a relaxed clock model appropriate for your data (e.g., uncorrelated lognormal, time-dependent) to account for rate variation among branches [36].
- Tree Prior: Choose a coalescent or birth-death prior that reflects the biological and epidemiological context. For epidemic spread, a skygrid or structured coalescent model may be appropriate [36] [84].
Execute MCMC Analysis:
- Configure the MCMC sampler in your software (e.g., BEAST X). For high-dimensional models, ensure that efficient transition kernels like HMC are enabled [36].
- Run the analysis for a sufficient number of generations to ensure convergence.
Diagnostic Checks:
- Use tools like
Tracerto analyze the MCMC output. Verify that ESS values for all key parameters are greater than 200, indicating adequate sampling from the posterior distribution [20]. - Check for convergence and mixing of the Markov chains.
- Use tools like
Posterior Summarization:
The Scientist's Toolkit
Table 2: Essential software and tools for Bayesian phylodynamic analysis with complex models.
| Tool Name | Type | Primary Function | Relevance to Partitioning & Complexity |
|---|---|---|---|
| BEAST X [36] | Software Package | Bayesian phylogenetic, phylogeographic, and phylodynamic inference. | The core inference platform that implements advanced clock, substitution, and coalescent models, plus HMC for efficient sampling. |
| PartitionFinder [83] | Software Tool | Selecting optimal partitioning schemes for phylogenetic datasets. | Implements greedy, strict hierarchical, and relaxed hierarchical clustering algorithms to find best-fit partitioning schemes. |
| TIGER / RatePartitions [82] | Software Tool | Calculating relative evolutionary rates and partitioning data accordingly. | Provides a data-driven method for partitioning alignments based on site-specific evolutionary rates. |
| PhyDyn [85] | BEAST 2 Package | Phylodynamic inference using complex compartmental epidemiological models. | Allows integration of mechanistic SIR-like models as priors, managing complexity through a flexible model definition language. |
| Tracer [20] | Analysis Tool | Diagnosing MCMC performance and summarizing posterior distributions. | Critical for assessing model convergence and ensuring parameter identifiability after a complex analysis. |
| BEAGLE [36] | Computational Library | High-performance likelihood calculation. | Used by BEAST X to accelerate computation, making complex partitioned models on large datasets feasible. |
Model Validation, Comparative Analysis, and Real-World Impact Assessment
Posterior Predictive Checks and Cross-Validation Techniques
In Bayesian phylodynamic analyses of epidemic spread, model reliability is paramount for drawing accurate inferences about parameters such as the basic reproductive number (( R_0 )), population growth rates, and evolutionary timescales. Model assessment techniques, primarily Posterior Predictive Checks (PPC) and Cross-Validation (CV), provide a framework for evaluating model adequacy and predictive performance. PPC assesses whether a model can generate data similar to the observed data, focusing on absolute model fit [86]. In contrast, CV evaluates a model's predictive accuracy on unseen data, facilitating relative model comparison [87]. Within phylodynamics, these methods help determine if a chosen model—incorporating assumptions about the molecular clock, demographic history, and substitution process—is suitable for describing the epidemiological data at hand [86] [36].
Theoretical Foundations
Posterior Predictive Checks
The core principle of PPC is that a well-fitting model should be able to generate replicated data, ( y^{rep} ), that is statistically similar to the observed data, ( y ). The posterior predictive distribution is formally defined as: [ p(y^{rep} | y) = \int p(y^{rep} | \theta) p(\theta | y) d\theta ] where ( \theta ) represents the model parameters [88]. This distribution integrates the likelihood of the replicated data, ( p(y^{rep} | \theta) ), over the posterior distribution of the parameters, ( p(\theta | y) ).
Model assessment is performed by comparing the observed data to the posterior predictive distribution using a test statistic or discrepancy measure, ( T(\cdot) ) [89] [88]. The posterior predictive probability (often called the p-value) is calculated as: [ P(T(y^{rep}) > T(y) | y) ] An extreme probability (very close to 0 or 1) suggests that the observed statistic is unlikely under the assumed model, indicating a lack of fit [89] [86]. A key strength of the Bayesian framework is the ability to use parameter-dependent discrepancy measures, ( D(y; \theta) ), which can probe specific model assumptions more powerfully [88].
Cross-Validation
While PPC assesses model adequacy, cross-validation focuses on predictive performance and model selection. The fundamental idea is to partition the data into a training set, used for model fitting, and a test set, used for evaluation. In a Bayesian context, the log-likelihood of the test data, given the posterior from the training set, is computed. The model with the highest mean log-likelihood on the test set is preferred [87].
Leave-One-Out Cross-Validation (LOO-CV) is a common variant where each data point is sequentially left out as the test set. However, exact LOO-CV is computationally expensive, leading to approximations like Pareto-smoothed importance sampling (PSIS) [90]. For complex models in phylogenetics, k-fold cross-validation (e.g., splitting the sequence alignment into k partitions) is often more practical [87].
Application in Phylodynamics
Model Adequacy with Posterior Predictive Checks
In phylodynamics, the "data" can be considered the observed phylogenetic tree derived from pathogen genetic sequences. PPC is used to test the absolute fit of phylodynamic models (e.g., coalescent, birth-death) and substitution models [86].
Table 1: Common Test Statistics for Phylodynamic PPC
| Test Statistic | Model Aspect Assessed | Interpretation |
|---|---|---|
| Tree Likelihood [86] | Overall Fit | Goodness-of-fit for the entire model. |
| Number of Taxa [86] | Sampling Model | Adequacy of the sampling assumption. |
| Tree Imbalance (e.g., Colless index) [86] | Demographic Process | Fit of the population growth/decline model. |
| Ratio of External to Internal Branch Lengths [86] | Demographic Process | Distinguishes exponential growth (long external branches) from constant population size. |
| Tree Height [86] | Molecular Clock | Calibration of the evolutionary timescale. |
| Number of Switches [89] | Trial Independence | For Binomial models, checks for runs of successes/failures. |
The workflow involves fitting the model to the empirical tree, then using posterior parameter samples to simulate many replicate trees. The distribution of the chosen test statistic across these replicate trees is compared to its value for the empirical tree. A model is considered inadequate if the empirical value falls in the tails of the predictive distribution [86]. For instance, if an exponential growth coalescent model consistently generates trees with a different balance than the observed tree, a different demographic model should be considered.
Model Selection with Cross-Validation
Cross-validation is particularly valuable for comparing non-nested models, such as different molecular clock hypotheses (e.g., strict vs. relaxed clock) or demographic models (e.g., constant-size vs. exponential-growth coalescent) [87].
A typical protocol for phylogenetic cross-validation involves splitting a multiple sequence alignment into a training set (e.g., 50% of sites) and a test set (the remaining 50%). The training set is used for full Bayesian inference, yielding a posterior distribution of chronograms (time-scaled trees). These chronograms are converted into phylograms (substitutions per site) using the posterior estimates of substitution rates. The phylogenetic likelihood of the test set is then calculated conditioned on these phylograms and other model parameters. The model with the highest mean predictive likelihood across multiple data partitions is preferred [87].
Table 2: Comparison of Model Assessment Techniques in Phylodynamics
| Feature | Posterior Predictive Checks (PPC) | Cross-Validation (CV) |
|---|---|---|
| Primary Goal | Absolute model fit (goodness-of-fit) | Relative model comparison (predictive accuracy) |
| Question Answered | "Is my model compatible with the data?" | "Which model predicts new data best?" |
| Computational Cost | Moderate (requires predictive simulations) | High (requires multiple model fits on training data) |
| Sensitivity to Priors | Less sensitive, focuses on likelihood | Can be sensitive, especially with sparse data [87] |
| Common Use Case | Identifying specific model failures (e.g., poor clock fit) | Choosing between clock or demographic models [87] |
Experimental Protocols
Protocol 1: PPC for a Phylodynamic Model
This protocol assesses the adequacy of a coalescent exponential-growth model for a viral phylogeny using the TreeModelAdequacy package in BEAST 2 [86].
1. Model Fitting:
- Specify the phylodynamic model (e.g., coalescent exponential-growth), clock model (e.g., relaxed lognormal), and substitution model in BEAST 2.
- Run an MCMC analysis to obtain a posterior distribution of parameters and the phylogenetic tree, ensuring all parameters have an effective sample size (ESS) > 200.
2. Posterior Predictive Simulation:
- Use the
TreeModelAdequacypackage to draw random samples from the posterior. - For each parameter sample, simulate a new phylogenetic tree using a built-in simulator (e.g., MASTER). This creates the posterior predictive distribution of trees.
3. Calculate Test Statistics:
- For both the empirical tree and each simulated tree, calculate one or more test statistics (see Table 1). The
TreeStat2package is recommended for this. - Example: To test the clock assumption, use the statistic for the number of substitutions per branch length.
4. Assess Adequacy:
- Compute the posterior predictive probability: the proportion of simulated trees where the test statistic ( T(y^{rep}) ) is more extreme than ( T(y) ).
- A value near 0.5 suggests a good fit, while a value <0.025 or >0.975 indicates a significant lack of fit [86].
Protocol 2: Cross-Validation for Clock Model Selection
This protocol uses CV to compare a strict clock model against an uncorrelated relaxed lognormal clock model [87].
1. Data Partitioning:
- Randomly split the sequence alignment into a training set (e.g., 50% of sites) and a test set (the other 50%), ensuring no site overlap.
2. Training Phase:
- Analyze the training set in BEAST 2 using each candidate model (e.g., strict clock and relaxed clock).
- Run a long MCMC chain (>10^7 steps, sampling every 5000), discarding 10% as burn-in. Ensure parameter ESS > 200.
- Save the posterior sample of parameters, including chronograms and evolutionary rates.
3. Predictive Evaluation:
- For each posterior sample from the training set:
- Convert the chronogram to a phylogram by multiplying branch lengths (time) by the evolutionary rate(s).
- Calculate the phylogenetic likelihood of the test set alignment conditioned on this phylogram and the other sampled model parameters.
- Compute the mean of these likelihoods for each model. The model with the higher mean predictive likelihood is preferred.
4. Replication and Final Selection:
- Repeat the partitioning and analysis process multiple times (e.g., 5-10) with different random splits to reduce sampling error.
- Select the model that demonstrates superior predictive performance across the majority of replicates.
The Scientist's Toolkit
Table 3: Essential Software and Packages for Model Assessment
| Tool / Package | Function | Application in Protocol |
|---|---|---|
| BEAST 2 [86] [36] | Core Bayesian phylogenetic inference platform. | Used for model fitting via MCMC in both PPC and CV protocols. |
| TreeModelAdequacy [86] | BEAST 2 package for posterior predictive simulation. | Automates the simulation of replicate trees in PPC (Protocol 1). |
| TreeStat2 [86] | Calculates summary statistics from phylogenetic trees. | Computes test statistics (e.g., tree imbalance) for empirical and simulated trees in PPC. |
| MASTER [86] | Stochastic simulator for phylogenetic trees. | Engine used by TreeModelAdequacy to simulate trees under the phylodynamic model. |
| P4 [87] | Phylogenetic software with Python scripting. | Can be used to calculate the phylogenetic likelihood of the test set in CV (Protocol 2). |
| General Computational Tools | ||
| R/python + ggplot2/Matplotlib | Statistical computing and visualization. | Used for calculating posterior predictive probabilities and creating comparison plots. |
| Tracer [86] | Diagnoses MCMC convergence. | Checks ESS and parameter sampling in the model-fitting step of all protocols. |
Robust model assessment is a critical step in Bayesian phylodynamic analysis. Posterior Predictive Checks and Cross-Validation offer complementary perspectives: PPC provides a powerful method for identifying specific model deficiencies by testing absolute fit, while CV offers a principled framework for selecting among competing models based on predictive performance. The integration of these methods into the analytical workflow, facilitated by the software tools outlined, ensures that inferences about epidemic spread—such as estimates of the reproductive number and growth rates—are based on models that are well-supported by the genetic sequence data.
Bayesian phylodynamic analysis has emerged as a powerful discipline for reconstructing the epidemiological dynamics of rapidly evolving pathogens by integrating genetic data with evolutionary models. This approach is particularly valuable for understanding the spread of viral variants during epidemics, as it leverages pathogen genomes sampled from infected hosts to infer signatures of epidemic spread [5]. This Application Note details the protocols and findings from a comprehensive comparative phylodynamic study of SARS-CoV-2 Variants of Concern (VOCs) in the Arabian Peninsula, providing a methodological framework for researchers investigating viral evolution and spread.
The study was framed within the broader context of utilizing Bayesian phylodynamic methods for epidemic spread research, focusing on the evolutionary history and dispersal patterns of five major variants (Alpha, Beta, Delta, Kappa, and Eta) that circulated in the region. By implementing a Bayesian phylodynamic pipeline, the research aimed to trace and compare the introduction events, evolutionary trajectories, and spread of these variants to guide intervention strategies and surveillance activities [91] [92]. The protocols outlined here demonstrate how genomic surveillance data can be transformed into actionable insights for public health decision-making, particularly in determining the allocation of resources toward the most relevant circulating variants.
Application Notes
Key Findings and Quantitative Results
The comparative phylodynamic analysis revealed distinct patterns of introduction and spread for each Variant of Concern across the Arabian Peninsula, with quantitative results summarized in the table below.
Table 1: Phylodynamic Parameters of SARS-CoV-2 Variants in the Arabian Peninsula
| Variant | Primary Introduction Source | Introduction Period | Epidemic Growth Pattern | Impact of Interventions |
|---|---|---|---|---|
| Alpha | Europe | Mid-2020 to Early 2021 | Sequential growth and decline | Reduced by NPIs* |
| Beta | Africa | Mid-2020 to Early 2021 | Sequential growth and decline | Reduced by NPIs* |
| Delta | East Asia | Early 2021 to Mid-2021 | Sequential growth and decline | Shaped by NPIs + Vaccination |
| Kappa | Multiple/Sporadic | Variable | Inconclusive/Sporadic | Limited established spread |
| Eta | Multiple/Sporadic | Variable | Inconclusive/Sporadic | Limited established spread |
*NPIs: Non-Pharmaceutical Interventions
The analysis identified that Alpha, Beta, and Delta variants underwent sequential periods of exponential growth followed by decline, whereas Kappa and Eta variants showed inconclusive population growth patterns due to their sporadic introduction patterns in the region [91]. Non-pharmaceutical interventions implemented between mid-2020 and early 2021 likely contributed to reducing the epidemic progression of Beta and Alpha variants, while the combination of these interventions with rapid vaccination rollout shaped Delta variant dynamics [91] [92].
The study further revealed significant and intense dispersal routes between the Arabian Peninsula and other global regions, including Africa, Europe, Asia, and Oceania, for the Alpha, Beta, and Delta variants [92]. These dispersal patterns were likely linked to air travel connectivity and the effectiveness of disease control interventions implemented across different countries in the region. In contrast, the restricted spread and stable effective population size inferred for Kappa and Eta variants suggested they no longer required targeted genomic surveillance activities in the region [91].
Impact on Public Health Decision-Making
The phylodynamic findings provided evidence-based guidance for public health authorities in the Arabian Peninsula. The confirmed dominance of Alpha, Beta, and Delta variants in recent outbreaks highlighted the necessity of focusing limited surveillance resources on these VOCs rather than the sporadically introduced Kappa and Eta variants [91]. The identification of specific introduction sources and periods enabled more targeted travel restrictions and screening protocols during subsequent waves of the pandemic.
The study underscored the urgent need to establish regional molecular surveillance programs to ensure effective decision-making regarding the allocation of intervention activities [92]. This approach allows for near real-time monitoring of variant-specific introduction events and their subsequent establishment in local populations, providing an early warning system for public health stakeholders.
Experimental Protocols
Bayesian Phylodynamic Pipeline
Table 2: Essential Research Reagents and Computational Tools
| Resource | Function/Application | Specifications |
|---|---|---|
| BEAST X | Bayesian phylogenetic inference | Cross-platform software with molecular clock and coalescent models [36] |
| Sequence Data | Viral genomic input | SARS-CoV-2 complete genomes with metadata |
| Markov Chain Monte Carlo (MCMC) | Posterior distribution sampling | Algorithm for statistical inference [5] |
| Molecular Clock Models | Evolutionary rate estimation | Uncorrelated relaxed clock with time-dependent variations [36] |
| Coalescent/Birth-Death Models | Population demographic history | Nonparametric Bayesian Skyline plot [93] |
| Discrete Trait Phylogeography | Spatial diffusion modeling | Continuous-time Markov chain for location transitions [94] |
Step-by-Step Workflow Protocol
Step 1: Data Collection and Curation
- Collect complete SARS-CoV-2 genomes from regional surveillance efforts with comprehensive metadata, including collection date, geographical location, and patient demographics [91].
- Obtain global background sequences from public databases (GISAID, GenBank) to provide phylogenetic context for introduction events.
- Perform quality control to remove sequences with ambiguous bases, sequencing errors, or incomplete metadata.
Step 2: Sequence Alignment and Recombination Screening
- Perform multiple sequence alignment using tools such as MUSCLE or MAFFT with default parameters [95].
- Manually adjust protein-coding regions using amino acid translation to ensure reading frame preservation.
- Screen for homologous recombination using RDP3 or similar tools, as recombination can confound phylogenetic inference [95].
Step 3: Phylogenetic Model Selection
- Select best-fitting substitution models using Bayesian Information Criterion (BIC) or similar statistical criteria [95].
- For SARS-CoV-2, consider mixed substitution models that account for site-specific and temporal rate heterogeneity [36].
- Validate temporal signal in the data using TempEst or similar regression-based methods [93].
Step 4: Bayesian Phylodynamic Analysis
- Configure BEAST X analysis using uncorrelated relaxed molecular clock models to account for rate variation among branches [36].
- Implement nonparametric Bayesian Skyline coalescent models to infer effective population size changes through time [93].
- Set up discrete trait phylogeographic analysis to reconstruct spatial diffusion history across the Arabian Peninsula [94].
- Run Markov Chain Monte Carlo (MCMC) sampling for sufficient generations (typically 100-500 million) to achieve parameter convergence, assessed through effective sample size (ESS) values >200 [91].
Step 5: Post-processing and Interpretation
- Use TreeAnnotator to generate maximum clade credibility trees after discarding appropriate burn-in (typically 10-20%).
- Utilize Tracer software to assess parameter convergence and model fit through ESS diagnostics and marginal likelihood estimation [93].
- Annotate phylogenetic trees with spatial and temporal information to visualize dispersal patterns and introduction events.
- Calculate Bayes Factors to test specific epidemiological hypotheses regarding transition rates between locations [94].
The following workflow diagram illustrates the complete analytical process:
Figure 1: Bayesian Phylodynamic Analysis Workflow
Variant-Specific Comparative Analysis Protocol
Introduction Metric Calculation:
- Identify distinct introduction events by clustering phylogenetic clades with ancestral nodes inferred outside the Arabian Peninsula [94].
- Calculate the probability that two randomly selected circulating lineages belong to the same introduced clade to quantify variant establishment success.
- Compute the proportion of singleton clades (containing only one sequence) to estimate variants with limited onward transmission.
Dispersal Dynamics Comparison:
- Perform discrete phylogeographic reconstruction to estimate supported transition events between locations within the Arabian Peninsula [94].
- Compare spatial diffusion patterns among variants using Bayes Factor tests for significant dispersal routes.
- Visualize variant-specific spread patterns using spatially annotated phylogenetic trees.
Effective Population Size Tracking:
- Estimate relative genetic diversity over time through nonparametric Bayesian Skyline plots [93].
- Compare population growth rates among variants to infer differences in epidemic potential.
- Corestimate population size changes with intervention timelines to assess control measure impact.
The following diagram illustrates the variant comparison methodology:
Figure 2: Variant Comparison Methodology
The implementation of this Bayesian phylodynamic protocol for analyzing SARS-CoV-2 Variants of Concern in the Arabian Peninsula demonstrates the powerful integration of genomic surveillance with statistical inference to guide public health response. The comparative approach revealed variant-specific signatures of evolution and spread linked to both air travel patterns and disease control interventions, providing actionable intelligence for epidemic response [91] [92]. The methodologies detailed in this protocol can be adapted for ongoing surveillance of SARS-CoV-2 evolution and applied to other rapidly evolving pathogens of public health concern.
The findings highlight the critical importance of establishing sustained regional molecular surveillance programs that enable real-time phylodynamic inference to identify emerging variants, trace their dispersal patterns, and evaluate the effectiveness of control measures. This approach represents a paradigm shift from reactive to proactive public health response, leveraging the rich information contained in pathogen genomes to inform intervention strategies and resource allocation decisions.
Benchmarking Against Traditional Phylogenetic Methods (e.g., Neighbor-Joining, Maximum Likelihood)
In the field of genomic epidemiology, accurately reconstructing the evolutionary history of pathogens is fundamental to understanding and controlling epidemic spread. Bayesian phylodynamic analysis has emerged as a powerful framework for integrating genetic sequence data with epidemiological models to estimate key parameters such as reproductive numbers and population dynamics [75]. However, the performance and reliability of these sophisticated methods must be evaluated against well-established traditional phylogenetic approaches, including distance-based methods like Neighbor-Joining (NJ) and character-based methods such as Maximum Likelihood (ML) [96]. This protocol provides a structured framework for benchmarking Bayesian phylodynamic inference against these traditional phylogenetic methods, enabling researchers to assess their comparative advantages and limitations in epidemic research contexts.
Background: Traditional Phylogenetic Methods
Traditional phylogenetic methods provide the foundational approaches for evolutionary inference against which newer Bayesian phylodynamic methods are compared.
Distance-Based Methods: These methods, including Neighbor-Joining (NJ) and Unweighted Pair Group Method with Arithmetic Mean (UPGMA), first convert molecular sequence data into a pairwise distance matrix, then apply clustering algorithms to infer evolutionary relationships [96]. The NJ method, developed by Saitou and Nei in 1987, uses an agglomerative clustering approach that starts with a star-like tree and iteratively merges the closest nodes until a complete tree is formed [96]. These methods are computationally efficient but may lose information during the distance calculation process, particularly when sequence divergence is substantial [96].
Character-Based Methods: These approaches operate directly on the sequence characters rather than pre-computed distances:
- Maximum Parsimony (MP): Based on Occam's razor principle, MP seeks the tree topology that requires the fewest evolutionary changes to explain the observed sequences [96]. It identifies informative sites and searches tree space for the topology minimizing nucleotide substitutions.
- Maximum Likelihood (ML): First proposed by Felsenstein, ML uses explicit probabilistic models of sequence evolution (e.g., JC69, K80, GTR) to find the tree topology and parameters that maximize the probability of observing the sequence data [96]. ML conducts heuristic searches through tree space due to the exponential increase in possible topologies with additional taxa.
Bayesian Phylodynamic Inference
Bayesian phylodynamic methods extend traditional approaches by incorporating time-structured sequence data with epidemiological population dynamic models to jointly infer evolutionary relationships and population parameters [75]. In Bayesian inference, the posterior probability of parameters (including the phylogenetic tree) is proportional to the product of the likelihood of the data under the model and the prior probability of the parameters [75]. Software implementations like BEAST 2 and the newer BEAST X platform enable this inference through Markov Chain Monte Carlo (MCMC) sampling, offering advanced clock models, substitution processes, and population dynamic models including birth-death-sampling processes [36] [75].
Comparative Framework: Key Metrics and Criteria
When benchmarking phylogenetic methods, researchers should evaluate performance across multiple dimensions using the following criteria:
Table 1: Key Metrics for Benchmarking Phylogenetic Methods
| Metric Category | Specific Metrics | Application in Epidemic Research |
|---|---|---|
| Topological Accuracy | Robinson-Foulds distance, branch support values, clade credibility | Accuracy in identifying transmission clusters and outbreak sources |
| Computational Efficiency | Runtime, memory usage, scalability to large datasets | Practical applicability during rapidly evolving outbreaks |
| Parameter Estimation | Accuracy of node heights, evolutionary rates, population parameters | Estimation of reproduction numbers (R), growth rates, and emergence dates |
| Uncertainty Quantification | Posterior probability distributions, bootstrap support, confidence intervals | Reliability of conclusions for public health decision-making |
| Statistical Consistency | Performance with increasing data, model misspecification robustness | Dependability across varying surveillance data quality |
Experimental Protocol for Benchmarking Analysis
The following diagram illustrates the comprehensive workflow for benchmarking phylogenetic methods in epidemic research contexts:
Data Preparation Protocol
Sequence Collection and Curation:
- Obtain pathogen genome sequences from public repositories (e.g., GISAID, NCBI Virus) with associated metadata including sampling dates and locations.
- For SARS-CoV-2 case studies, focus on specific outbreak scenarios: nosocomial outbreaks, community transmission clusters, or regional spread patterns [75].
Multiple Sequence Alignment (MSA):
- Perform alignment using appropriate methods: ProbCons, MAFFT, or Clustal for protein-coding genes.
- For protein-coding genes, translate to amino acids, align at protein level, then back-translate to DNA using tools like DAMBE or Pal2Nal [97].
- Trim unreliably aligned regions using automated tools (e.g., TrimAl) or manual inspection while preserving phylogenetic signal [96].
Simulated Data Generation (Optional but Recommended):
- Simulate sequence evolution along known benchmark trees using software like INDELible or Seq-Gen.
- Incorporate epidemiological parameters (e.g., time-varying reproduction numbers, heterogeneous sampling) to reflect realistic outbreak scenarios.
- Use birth-death-sampling processes to generate trees with known transmission history for method validation [75].
Method Implementation Protocols
Neighbor-Joining Protocol
Distance Matrix Calculation:
- Compute pairwise distances using appropriate nucleotide substitution models (e.g., Jukes-Cantor, Kimura 2-parameter).
- Command line example (PHYLIP):
dnadist -data -model F84 -output
Tree Construction:
- Apply neighbor-joining algorithm to distance matrix.
- Command line example (PHYLIP):
neighbor -data -method nj -output - Bootstrap resampling (100-1000 replicates) for branch support assessment.
Maximum Likelihood Protocol
Model Selection:
- Identify best-fitting substitution model using ModelTest-NG or jModelTest2 based on AIC/BIC criteria.
- Common models: HKY85, GTR+Γ+I for nucleotide data.
Tree Search:
- Perform heuristic tree search using RAxML or IQ-TREE.
- Command line example (RAxML):
raxmlHPC -s alignment.phy -n tree1 -m GTRGAMMA -p 12345 -# 20 - Apply thorough search strategies: multiple random addition sequences, subtree pruning and regrafting (SPR) moves.
Branch Support Assessment:
- Perform standard non-parametric bootstrap (100-1000 replicates) or faster approximation methods (e.g., UFBoot) [98].
Bayesian Phylodynamic Protocol
Model Specification in BEAST 2:
- Clock Model: Select appropriate molecular clock (strict, uncorrelated relaxed, random local clock) based on data characteristics [36].
- Substitution Model: Implement site-heterogeneous models (e.g., Markov-modulated models) or random-effects substitution models when appropriate [36].
- Tree Prior: Apply birth-death-sampling models for epidemic data, enabling direct estimation of reproductive numbers (R) and sampling proportions [75].
- Partitioning: Implement separate substitution models for different genomic regions when applicable.
MCMC Configuration:
- Run multiple independent chains (minimum 2) for adequate sampling of posterior distribution.
- Set appropriate chain lengths (10-100 million generations) based on dataset size and model complexity.
- Monitor convergence using ESS (Effective Sample Size) values >200 for all parameters in Tracer.
Post-processing:
- Generate maximum clade credibility (MCC) tree after discarding appropriate burn-in (10-25%).
- Summarize parameter estimates (mean, 95% HPD intervals) for epidemiological interpretation.
Evaluation and Analysis Protocol
Topological Assessment:
- Calculate Robinson-Foulds distances between inferred trees and reference (simulated or trusted) trees.
- Compare branch support values (posterior probabilities vs. bootstrap proportions) across methods.
- Assess clade credibility for key epidemiological groupings (transmission clusters, geographic isolates).
Parameter Accuracy Evaluation:
- Compare node height estimates (divergence times) against known sampling dates.
- Evaluate precision and accuracy of evolutionary rate estimates.
- For Bayesian methods, assess accuracy of epidemiological parameters (R, growth rates) against known values from simulated data or independent epidemiological estimates.
Computational Performance Analysis:
- Record runtime and memory usage for each method under standardized computing environments.
- Assess scalability by analyzing performance with increasing taxon sampling (100, 1000, 10,000 sequences).
- Evaluate convergence rates for Bayesian methods (time to stationarity, mixing efficiency).
Uncertainty Quantification Comparison:
- Compare breadth and calibration of confidence intervals (frequentist) and credible intervals (Bayesian).
- Assess robustness to model misspecification through simulation studies.
- Evaluate performance with incomplete or biased sampling characteristic of outbreak data.
Table 2: Essential Computational Tools for Phylogenetic Benchmarking
| Tool/Resource | Type | Primary Function | Application Context |
|---|---|---|---|
| BEAST 2 / BEAST X [36] [75] | Software Package | Bayesian evolutionary analysis | Phylodynamic inference with integrated epidemiological parameters |
| RAxML [98] | Software Package | Maximum likelihood inference | High-performance phylogenetic estimation |
| PHYLIP | Software Package | Distance-based methods | Neighbor-joining and other distance matrix approaches |
| IQ-TREE | Software Package | Maximum likelihood inference | Model selection and fast likelihood estimation |
| Tracer | Analysis Tool | MCMC diagnostics | Assessing convergence and parameter estimates |
| TreeAnnotator | Utility Program | Tree summarization | Generating maximum clade credibility trees |
| ModelTest-NG | Software Package | Model selection | Identifying best-fitting substitution models |
| R/phangorn | R Package | Phylogenetic analysis | Tree comparison, distance calculations, visualization |
Anticipated Results and Interpretation
Performance Expectations Across Methods
The benchmarking exercise will likely reveal method-specific performance patterns:
Neighbor-Joining: Expected to demonstrate superior computational speed but potentially reduced accuracy with increasing sequence divergence and complex evolutionary scenarios [96]. Suitable for initial exploratory analysis of large datasets.
Maximum Likelihood: Anticipated to show good balance between accuracy and efficiency, with strong performance in topological estimation, particularly with appropriate model selection [96]. May struggle with full integration of epidemiological parameters.
Bayesian Phylodynamics: Expected to provide integrated epidemiological inference and comprehensive uncertainty quantification but with substantially higher computational demands [75]. Particularly advantageous for estimating time-structured processes and population dynamic parameters directly relevant to epidemic spread.
Method Selection Guidelines
The following decision diagram provides guidance for selecting appropriate phylogenetic methods based on research objectives and constraints:
This protocol provides a comprehensive framework for benchmarking Bayesian phylodynamic methods against traditional phylogenetic approaches in epidemic research contexts. Through systematic evaluation across multiple performance dimensions, researchers can make informed decisions about method selection based on their specific research questions, data characteristics, and computational resources. The iterative benchmarking approach outlined here facilitates methodological refinement and enhances the reliability of phylogenetic inferences in critical public health applications. As Bayesian methods continue to evolve with improved computational efficiency and more sophisticated models [36], ongoing benchmarking will remain essential for advancing the field of genomic epidemiology and strengthening our response to infectious disease threats.
Assessing the Impact of Phylodynamics on Public Health Decision-Making
Article Information
Article Title: Assessing the Impact of Phylodynamics on Public Health Decision-Making Content Type: Application Notes and Protocols Thesis Context: Bayesian phylodynamic analysis for epidemic spread research Audience: Researchers, scientists, and drug development professionals
Bayesian phylodynamic models have revolutionized epidemiological studies by enabling researchers to infer key aspects of the geographic history and transmission dynamics of disease outbreaks directly from pathogen genetic sequence data [99] [10]. These approaches combine evolutionary, demographic, and epidemiological concepts to reconstruct pathogen spread through space and time, providing a powerful framework for understanding and combating epidemics [10]. The COVID-19 pandemic marked a turning point where large-scale, real-time genomic sequencing and phylodynamic analysis became central to public health decision-making, with nearly 400,000 SARS-CoV-2 genomes generated and shared publicly within the first year of the pandemic [10]. This application note details the methodological protocols, analytical frameworks, and implementation guidelines for applying Bayesian phylodynamic analysis to epidemic spread research, with particular emphasis on translating computational inferences into actionable public health insights.
Key Concepts and Definitions
Table 1: Core Phylodynamic Concepts and Their Public Health Applications
| Concept | Technical Definition | Public Health Relevance |
|---|---|---|
| Phylodynamics | A framework that combines evolutionary, demographic and epidemiological concepts to infer population parameters directly from genetic data [10] [100]. | Enables tracking of virus genetic changes, identification of emerging variants, and informs public health strategy. |
| Discrete Trait Analysis (DTA) | Models geographic history as dispersal among discrete areas (e.g., cities, states) over pathogen phylogeny branches [99] [10]. | Infers importation routes and spatial spread patterns to target travel restrictions and local interventions. |
| Structured Birth-Death (BD) Models | Explicitly models migration events and rates at population level, accounting for variable sampling between regions [10]. | Provides parameters comparable with epidemiological/mobility data; more robust to sampling bias than DTA. |
| Multitype Population Trajectories | Infers trait-specific population sizes, infected host counts, or other demographic quantities through time [100]. | Elucidates properties of populations not directly ancestral to sampled members, such as spillover events. |
| Molecular Clock Dating | Estimates evolutionary rates and timescales using genetic substitutions calibrated with sampling dates [10] [101]. | Determines outbreak origins, timing of spread, and impact of interventions. |
Quantitative Data Synthesis
Table 2: Key Epidemiological Parameters Inferable from Phylodynamic Models
| Parameter | Inference Method | Public Health Application | Data Requirements |
|---|---|---|---|
| Effective Reproductive Number (Rt) | Birth-Death skyline models [10] | Measure intervention effectiveness; estimate Rt reduction from 1.63 to 0.48 in Australia post-interventions [10]. | Time-stamped sequences, proportion of cases sequenced. |
| Lineage Introduction Events | Discrete phylogeographic models [10] | Quantify imported vs. local transmission; 104 international introductions to Brazil in March-April 2020 [10]. | Geographically annotated sequences, travel data. |
| Dispersal Rates Between Locations | Continuous-time Markov chain (CTMC) models [99] | Identify important transmission routes; prioritize surveillance and control measures. | Symmetric or asymmetric location data. |
| Time to Most Recent Common Ancestor (tMRCA) | Molecular clock dating [10] [101] | Estimate outbreak timing; revealed SARS-CoV-2 establishment in Italy by mid-February 2020 [10]. | Precise sampling dates, clock model selection. |
| Variant Emergence and Spread | Multitype birth-death models [100] | Track variants of concern; multiple B.1.1.7 introductions to US with 9.8-day doubling time [10]. | Variant-defining mutations, representative sampling. |
Experimental Protocols and Workflows
Protocol: Discrete Phylogeographic Analysis for Route Identification
Purpose: To identify significant pathogen dispersal routes between geographic locations and quantify their relative rates.
Materials and Reagents:
- Pathogen genomic sequences with known sampling locations
- Computational resources (high-performance computing cluster recommended)
- BEAST 2.5 or BEAST X software package [99] [36]
- Associated packages (BEAST, MASTER, multiTypeTree)
Procedure:
- Sequence Alignment: Perform multiple sequence alignment using MAFFT or MUSCLE; visually inspect for quality.
- Substitution Model Selection: Use ModelTest-NG or bModelTest to determine optimal nucleotide substitution model.
- Molecular Clock Model Selection: Compare strict clock vs. relaxed clock models using marginal likelihood estimation.
- Spatial Model Configuration:
- Define discrete geographic traits (countries, states, or regions)
- Specify symmetric or asymmetric dispersal model based on hypothesis
- Select appropriate prior distributions (see Section 4.3)
- Markov Chain Monte Carlo (MCMC) Execution:
- Run 2-4 independent chains for 50-100 million generations
- Check convergence (ESS > 200 for all parameters)
- Combine logs and trees from multiple runs using LogCombiner
- Posterior Analysis:
- Annotate maximum clade credibility tree using TreeAnnotator
- Visualize spatial spread using SpreaD3 or other visualization tools
- Calculate Bayes factors for supported dispersal routes
Troubleshooting: If ESS values remain low, consider increasing chain length, adjusting operator weights, or using Hamiltonian Monte Carlo (HMC) samplers available in BEAST X [36].
Protocol: Reproductive Number Estimation Through Time
Purpose: To infer temporal changes in the effective reproductive number (Rt) from genomic data.
Materials and Reagents:
- Time-stamped pathogen genomes
- Birth-death model implementation (BEAST 2.5+)
- Skyline plot package
Procedure:
- Data Preparation: Ensure accurate sampling dates; address date-rounding issues per Section 5.2.
- Model Specification: Configure birth-death skyline model with appropriate epoch boundaries.
- Prior Specification: Set informed priors based on epidemiological context.
- MCMC Execution: Run extended analyses (100M+ generations) to ensure precise Rt estimates.
- Skyline Plot Generation: Extract and visualize Rt through time with 95% highest posterior density intervals.
Validation: Compare Rt estimates with epidemiological surveillance data where available.
Methodological Considerations and Optimization
Addressing Prior Sensitivity in Bayesian Phylodynamics
Table 3: Strategies for Appropriate Prior Selection in Phylodynamic Inference
| Challenge | Default Prior Issue | Recommended Solution | Implementation |
|---|---|---|---|
| Average Dispersal Rate | Strong and biologically unrealistic assumptions in ≈93% of studies [99] | Use more biologically reasonable priors based on epidemiological knowledge | BEAST X's new Hamiltonian Monte Carlo samplers [36] |
| Number of Dispersal Routes | Offset Poisson prior favors minimal number of routes [99] | Specify informed priors based on connectivity data | Incorporate travel volume or mobility data as predictors |
| Sampling Bias | Inadequate accounting for heterogeneous sampling across regions [102] [10] | Use structured coalescent models that accommodate variable sampling | Multi-type tree models in BEAST 2.5+ [36] |
| Missing Data | Exclusion of sequences with incomplete metadata | Integrate out missing data within Bayesian framework | BEAST X's HMC approach for missing predictor values [36] |
Managing Sampling Date Precision
Reduced date resolution threatens inference accuracy and patient confidentiality. The critical threshold for bias occurs when date uncertainty exceeds the average time for a substitution to arise in the pathogen [101].
Protocol: Sampling Date Handling for Privacy and Accuracy
- Assessment: Calculate expected substitutions per year based on genome size and evolutionary rate.
- Resolution Determination: Maintain date precision sufficient to resolve substitutions (typically day-level for rapidly evolving viruses).
- Anonymization: For sensitive data, translate all dates uniformly by a random number rather than reducing resolution [101].
- Analysis: Incorporate date uncertainty explicitly in Bayesian inference when low-resolution dates are unavoidable.
Visualization and Computational Tools
Phylodynamic Analysis Workflow
Figure 1: Bayesian Phylodynamic Analysis Workflow for Public Health
Key Software and Analytical Tools
Table 4: Essential Research Reagent Solutions for Phylodynamic Analysis
| Tool/Platform | Function | Application Note |
|---|---|---|
| BEAST X [36] | Bayesian evolutionary analysis sampling trees | Latest platform with Hamiltonian Monte Carlo samplers for improved scalability; integrates sequence evolution, phylodynamics, and phylogeography. |
| Nextstrain [102] [10] | Real-time genomic epidemiology visualization | Custom analyses for investigating transmission clusters; used for situation reports during Ebola and COVID-19 outbreaks. |
| UShER [102] | Ultrafast sample placement on existing trees | Rapid phylogenetic placement of new SARS-CoV-2 sequences into global tree structure. |
| SpreaD3 [10] | Phylogeographic visualization | Animates spatial spread of pathogens over time; creates publication-quality figures. |
| BEAGLE [36] | High-performance computational library | Accelerates phylogenetic likelihood calculations; enables analysis of larger datasets. |
Implementation in Public Health Decision-Making
Expert Recommendations for Effective Translation
Focus groups with 23 experts in public health, infectious diseases, virology, and bioinformatics identified nine major themes for successful phylodynamic implementation [102] [103]:
- Strengthen Academic-Public Health Partnerships: Collaborative frameworks essential for translating analytical insights into field operations.
- Develop Interoperability Standards: Standardized sequence data sharing protocols critical for comparative analyses.
- Ensure Careful Scientific Communication: Mitigate misinterpretation risks through clear reporting of methodological limitations.
- Address Resource Limitations: Computational infrastructure and trained personnel requirements must be considered in public health budgeting.
- Tailor Responses to Specific Variants: Precision public health approaches leveraging variant-specific characteristics.
Protocol: Integrating Phylodynamics into Public Health Response
Purpose: To establish a framework for incorporating phylodynamic insights into ongoing public health decision-making.
Procedure:
- Rapid Sequencing: Implement targeted sequencing during outbreaks with 72-hour turnaround.
- Real-time Analysis: Deploy automated pipelines for initial phylogenetic placement and cluster identification.
- Contextual Interpretation: Integrate genomic insights with epidemiological and clinical data.
- Stakeholder Communication: Develop standardized reporting templates for different audience types (administrators, field staff, policymakers).
- Intervention Adjustment: Use phylodynamic evidence to refine containment strategies, travel policies, and resource allocation.
Case Example: During COVID-19, phylogeographic analyses revealed the shift in global SARS-CoV-2 dissemination from China to Europe and associated spread of D614G spike mutation, informing targeted travel restrictions [10].
Bayesian phylodynamic analysis represents a powerful methodology for elucidating epidemic spread and informing public health decision-making. The protocols and application notes detailed herein provide researchers and public health professionals with standardized approaches for implementing these analyses while addressing common methodological challenges. As the field advances with improved computational methods in BEAST X [36] and better strategies for managing data limitations [99] [101], the integration of phylodynamics into public health practice will continue to enhance our ability to respond effectively to infectious disease threats. Successful implementation requires both technical rigor in analysis and strong collaborative frameworks between academic researchers and public health practitioners [102] [103].
Validation Frameworks for Emerging Technologies like CRISPR-Based Lineage Tracing
Cell lineage tracing is a foundational technology for describing the developmental history of individual progenitor cells and assembling them into lineage development trees [104]. Traditional methods have faced significant limitations in stability and resolution, but the emergence of CRISPR-Cas9 gene editing has revolutionized this field by enabling precise introduction of genetic markers that can be tracked across cell generations [104]. Within the context of epidemic spread research, these lineage tracing techniques provide powerful analogs for understanding pathogen evolution and transmission dynamics. The core principle involves using CRISPR-Cas9 to introduce unique, heritable DNA barcodes into individual cells or pathogens, which then accumulate spontaneous mutations as they proliferate, generating distinct molecular signatures that record lineage relationships and differentiation trajectories [104].
The integration of these approaches with Bayesian phylodynamic analysis creates a robust framework for reconstructing population trajectories from genetic data, enabling researchers to infer critical parameters such as transmission rates, population sizes, and evolutionary dynamics directly from genomic information [100]. This synthesis is particularly valuable for understanding the spread of epidemics, where lineage tracing can reveal both the historical relationships between pathogen strains and the underlying population dynamics driving infection spread.
Core Methodologies and Experimental Protocols
CRISPR-Cas9-Mediated Lineage Tracing Techniques
The fundamental mechanism of CRISPR-based lineage tracing relies on the RNA-guided, DNA-targeting capability of the Cas9 nuclease. Single-guide RNA (sgRNA) directs Cas9 to induce double-strand breaks at specific DNA sequences, triggering cellular repair mechanisms that generate genetic markers [104]. These edits occur primarily through two pathways:
- Non-homologous end joining (NHEJ): This error-prone repair pathway generates random insertion or deletion mutations (indels) that form unique genetic barcodes [104] [105].
- Homology-directed repair (HDR): This pathway enables precise gene insertion when a donor template is provided, allowing for introduction of specific markers [105].
These genetic markers are stably inherited during cell division, creating a record of lineage relationships that can be decoded through sequencing [104]. Advanced implementations now employ inducible CRISPR-Cas9 systems that activate Cas9 at specific time points, enabling continuous recording of development and dynamically capturing changes in cell states over extended periods [104].
Table 1: Comparison of Major CRISPR-Cas9 Lineage Tracing Techniques
| Method | Core Principle | Key Applications | Advantages | Limitations |
|---|---|---|---|---|
| GESTALT [106] | Cas9-induced stochastic mutations in a barcode array | Whole-organism developmental lineage tracing | High-resolution tracking | Mutation saturation over time |
| scGESTALT [106] | Combines GESTALT with single-cell transcriptomics | Linking cell states and lineage history | Simultaneous lineage and transcriptome data | Computational challenges in integration |
| LinTIMaT [106] | Statistical integration of mutations with transcriptomics | Resolving ambiguous lineage relationships | Improved cell type coherence | Complex statistical implementation |
| DuTracer [107] | Dual-nuclease (Cas9 and Cas12a) editing | Complex lineage relationships in embryoid bodies | Minimal target dropouts, deeper tree depths | Requires optimization of two systems |
Detailed Experimental Protocol: Dual-Nuclease Lineage Tracing
The DuTracer protocol represents an advanced approach that utilizes two orthogonal gene editing systems to record cell lineage history at single-cell resolution [107]. The following protocol details the key steps for implementation:
Step 1: Vector Design and Construction
- Design a barcode array containing multiple target sites for both Cas9 and Cas12a nucleases
- Clone this array into an appropriate vector backbone with regulatory elements for inducible expression
- Incorporate features for single-cell sequencing, such as UMIs (Unique Molecular Identifiers) and cell barcodes
Step 2: Delivery and Induction
- Deliver the construct to target cells via lentiviral transduction or electroporation
- Administer tamoxifen or other inducters at specific time points to activate the Cas9/Cas12a system
- Allow sufficient time for barcode editing and accumulation of lineage information
Step 3: Single-Cell Sequencing Library Preparation
- Harvest cells at experimental endpoint and prepare single-cell suspensions
- Generate single-cell libraries using appropriate platforms (10X Genomics, Drop-seq, etc.)
- Amplify barcode regions with targeted PCR and prepare sequencing libraries
Step 4: Sequencing and Data Generation
- Sequence libraries using high-throughput platforms (Illumina NovaSeq, MiSeq, etc.)
- Target sequencing depth: >50,000 reads per cell for transcriptome, >100x coverage for barcodes
- Include control samples with known barcodes for quality assessment
Workflow Visualization: CRISPR Lineage Tracing with Bayesian Integration
Validation Frameworks and Quality Control
CRISPR Editing Efficiency Assessment
Validating CRISPR editing efficiency is crucial for ensuring robust lineage tracing data. Multiple methods exist for this purpose, each with distinct advantages and limitations [105] [108].
Table 2: Comparison of CRISPR Analysis Methods for Validation
| Method | Principle | Sensitivity | Quantitative Capability | Best Use Cases |
|---|---|---|---|---|
| Next-Generation Sequencing (NGS) [105] [108] | Direct sequencing of target region | Very High (<0.1% variant detection) | Excellent (Precise quantification) | Gold standard validation; publication-quality data |
| ICE (Inference of CRISPR Edits) [105] | Computational analysis of Sanger data | High (Correlates with NGS: R²=0.96) | Very Good | High-throughput screening; cost-effective validation |
| TIDE (Tracking Indels by Decomposition) [105] [108] | Decomposition of Sanger chromatograms | Moderate | Good (Limited for complex edits) | Rapid assessment of editing efficiency |
| T7E1 Assay [108] | Enzyme cleavage of mismatched DNA | Low (Poor detection <10% or >90%) | Poor (Non-quantitative) | Initial screening; low-budget confirmation |
Recommended Validation Protocol:
- Initial assessment using T7E1 assay for rapid screening of multiple sgRNAs
- Intermediate validation with ICE or TIDE for quantitative analysis of promising candidates
- Final validation using targeted NGS for comprehensive characterization of editing efficiency and spectrum
Computational Integration with Bayesian Frameworks
The integration of lineage tracing data with Bayesian phylodynamic models requires specialized computational approaches. The LinTIMaT (Lineage Tracing by Integrating Mutation and Transcriptomic data) method addresses key challenges by employing a maximum-likelihood framework that combines mutation data with transcriptomic information [106].
LinTIMaT Statistical Framework:
- Mutation likelihood: Implements Camin-Sokal parsimony criterion for each synthetic marker, with transition probabilities computed based on marker abundance in single cells
- Expression likelihood: Models lineage as Bayesian hierarchical clustering (BHC), computing marginal likelihoods of partitions consistent with the lineage tree using Dirichlet process mixture model
- Tree optimization: Employs heuristic search algorithm that stochastically explores lineage tree space, first inferring trees based on mutation information then refining with expression data
Bayesian Phylodynamic Integration: Advanced Bayesian methods enable inference of multitype population trajectories directly from genetic data [100]. These approaches:
- Treat population heterogeneity by assigning individuals to different discrete types
- Infer type-specific population size functions with minimal additional computational cost
- Reconstruct demographic quantities such as infection numbers through time and transmission events between populations
Research Reagent Solutions
Table 3: Essential Research Reagents for CRISPR Lineage Tracing
| Reagent Category | Specific Examples | Function | Considerations |
|---|---|---|---|
| Nuclease Systems | S. pyogenes Cas9, Cas12a [107] | Induce targeted DNA breaks for barcode editing | Orthogonal systems reduce target dropout |
| Delivery Vectors | Lentiviral vectors, PiggyBac transposon | Stable integration of barcode arrays | Optimize for cell type-specific delivery |
| Inducible Systems | Cre-ERT2, Dre-rox [109] | Temporal control of editing activation | Titrate inducer (e.g., Tamoxifen) for sparse labeling |
| Barcode Arrays | Synthetic target site arrays | Recording lineage information | Design with multiple target sites per nuclease |
| Sequencing Reagents | 10X Genomics Single Cell Kit | Simultaneous barcode and transcriptome capture | Optimize cell viability and recovery |
| Validation Tools | T7E1 enzyme, ICE analysis software [105] [108] | Assess editing efficiency and specificity | Use tiered approach from screening to validation |
Advanced Applications in Phylodynamic Research
Workflow Visualization: Bayesian Phylodynamic Inference
Integration with BEAST X for Phylodynamic Inference
The BEAST X software platform provides advanced capabilities for integrating lineage tracing data with Bayesian phylodynamic inference [36]. Key features include:
Novel Substitution Models:
- Markov-modulated models (MMMs): Allow substitution processes to change across each branch and site independently, capturing different selective pressures over site and time [36]
- Random-effects substitution models: Extend standard continuous-time Markov chain models to capture additional rate variation and non-reversibility in substitution processes [36]
Advanced Clock Models:
- Time-dependent evolutionary rate models: Accommodate evolutionary rate variations through time, particularly relevant for rapidly evolving pathogens [36]
- Shrinkage-based local clock models: Provide tractable and interpretable modeling of rate heterogeneity across lineages [36]
Computational Advancements:
- Hamiltonian Monte Carlo (HMC) sampling: Enables efficient exploration of high-dimensional parameter spaces, significantly increasing effective sample size per unit time compared to conventional methods [36]
- Preorder tree traversal algorithms: Enable linear-time calculations of high-dimensional gradients for branch-specific parameters [36]
Protocol Implementation and Troubleshooting
Optimized Protocol for High-Quality Lineage Tracing
Critical Steps for Success:
- Barcode Array Design: Incorporate 10-20 target sites per nuclease with varying efficiencies to minimize saturation
- Delivery Optimization: Titrate viral vectors to achieve single-copy integration in most cells
- Induction Timing: Space inducer treatments to capture developmental transitions without excessive editing
- Single-Cell Preparation: Maintain cell viability >90% throughout dissociation and library preparation
- Sequencing Depth: Target >50,000 reads/cell for transcriptome and >100x coverage for barcodes
Troubleshooting Common Issues:
- Low editing efficiency: Optimize sgRNA design, verify nuclease activity, improve delivery efficiency
- Barcode dropout: Reduce target site saturation, use dual-nuclease systems [107], optimize sequencing depth
- Poor single-cell recovery: Optimize dissociation protocol, use viability-enhancing reagents, filter dead cells
- Computational integration challenges: Implement LinTIMaT [106] or similar integration methods, validate with simulated data
Validation and Quality Control Metrics
Essential QC Metrics:
- Editing efficiency: >70% cells show barcode modifications (verified by NGS)
- Cell doublet rate: <5% in single-cell sequencing
- Barcode recovery: >80% cells with usable barcode information
- Tree consistency: High concordance between mutation-based and expression-based lineages
- Bayesian convergence: ESS >200 for key parameters in BEAST X analyses [36]
This comprehensive validation framework ensures robust integration of CRISPR-based lineage tracing with Bayesian phylodynamic analysis, enabling reliable inference of population trajectories and evolutionary dynamics in epidemic research.
Conclusion
Bayesian phylodynamics provides a powerful, unified framework for reconstructing epidemic spread by integrating genomic data with evolutionary and epidemiological models. The synthesis of foundational principles, advanced methodologies, and robust troubleshooting techniques enables researchers to accurately trace viral origins, quantify transmission dynamics, and assess intervention impacts. Future directions include leveraging emerging technologies like CRISPR-based lineage tracing, integrating heterogeneous data sources through hierarchical models, and enhancing real-time surveillance capabilities. For biomedical and clinical research, these advances promise to refine outbreak response, optimize vaccine development, and strengthen genomic surveillance systems for more effective public health outcomes.
References
- 1. Application of Bayesian approaches in drug development [https://pmc.ncbi.nlm.nih.gov/articles/PMC9931171/]
- 2. Understanding the Prior and the Posterior Distributions [https://sarowarahmed.medium.com/understanding-the-prior-and-the-posterior-distributions-0f36f8737ecc]
- 3. Bayesian Inference of Phylogenetic Distances: Revisiting ... [https://link.springer.com/article/10.1007/s11538-024-01403-z]
- 4. Bayesian inference of phylogenetic trees is not misled by ... [https://www.cambridge.org/core/journals/paleobiology/article/bayesian-inference-of-phylogenetic-trees-is-not-misled-by-correlated-discrete-morphological-characters/C674B85D5D4ED7DB4DB4FA44DECA1D6D]
- 5. Getting to the root of epidemic spread with phylodynamic ... [https://pubmed.ncbi.nlm.nih.gov/26139467/]
- 6. What are the applications of phylogeny analysis in drug ... [https://synapse.patsnap.com/article/what-are-the-applications-of-phylogeny-analysis-in-drug-discovery]
- 7. Phylodynamic applications in 21st century global infectious ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5683535/]
- 8. Estimating pathogen spread using structured coalescent ... [https://www.sciencedirect.com/science/article/pii/S1755436524000562]
- 9. Robust Phylodynamic Analysis of Genetic Sequencing ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9413058/]
- 10. Phylogenetic and phylodynamic approaches to ... [https://www.nature.com/articles/s41576-022-00483-8]
- 11. Sampling through time and phylodynamic inference with ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4223917/]
- 12. Phylodynamic Analysis | 176 genomes | 6 Mar 2020 [https://virological.org/t/phylodynamic-analysis-176-genomes-6-mar-2020/356]
- 13. Advances in approximate Bayesian inference for models in ... [https://www.sciencedirect.com/science/article/pii/S175543652500043X]
- 14. Effective Population Size Estimation in Large Marine ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12304085/]
- 15. Spatiotemporal reproduction number with Bayesian model ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10010957/]
- 16. Estimating the effective reproduction number from ... [https://www.sciencedirect.com/science/article/pii/S1755436525000271]
- 17. Epidemiological hypothesis testing using a ... [https://www.nature.com/articles/s41467-020-19122-z]
- 18. Estimating the optimal number of samples to determine ... [https://www.frontiersin.org/journals/genetics/articles/10.3389/fgene.2025.1588986/full]
- 19. Accelerated Bayesian inference of population size history ... [https://www.nature.com/articles/s41588-025-02323-x]
- 20. A biologist's guide to Bayesian phylogenetic analysis - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC5624502/]
- 21. Bayesian estimation of the time-varying reproduction ... [https://www.sciencedirect.com/science/article/pii/S2468042724000691]
- 22. Bayesian phylodynamic analyses [https://bio-protocol.org/exchange/minidetail?id=15313911&type=30]
- 23. Advances in Visualization Tools for Phylogenomic and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6688121/]
- 24. Reconstructing the initial global spread of a human influenza pandemic – PLOS Currents Influenza [https://currents.plos.org/influenza/article/reconstructing-the-initial-global-spread-of-a-human-influenza-pandemic/index.html]
- 25. PhyloScape: interactive and scalable visualization platform for ... [https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-025-06203-3]
- 26. Top five metadata management best practices [https://www.collibra.com/blog/metadata-management-best-practices]
- 27. Creating and Implementing a Metadata Strategy [https://www.dataversity.net/articles/creating-and-implementing-a-metadata-strategy/]
- 28. Essential Metadata Strategy for Effective Data Management [https://www.ewsolutions.com/metadata-strategy-overview/]
- 29. Bayesian inference in phylogeny [https://en.wikipedia.org/wiki/Bayesian_inference_in_phylogeny]
- 30. Chapter 7 Bayesian phylogenetics [http://dunnlab.org/phylogenetic_biology/bayesian-phylogenetics.html]
- 31. A Bayesian Inference Framework to Reconstruct ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3499255/]
- 32. Phylodynamic inference of the contribution of transmission ... [https://www.medrxiv.org/content/10.1101/2025.06.17.25329759v1]
- 33. Bayesian Inference of Pathogen Phylogeography using the ... [https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1012995]
- 34. BEAST 2: A Software Platform for Bayesian Evolutionary ... [https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1003537]
- 35. Frequently Asked Questions | BEAST Documentation [https://beast.community/faq.html]
- 36. BEAST X for Bayesian phylogenetic, phylogeographic and ... [https://www.nature.com/articles/s41592-025-02751-x]
- 37. BEAST X for Bayesian phylogenetic, phylogeographic and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12328226/]
- 38. BEAST 2.5: An advanced software platform for Bayesian ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6472827/]
- 39. Introduction to BEAST2 [https://taming-the-beast.org/tutorials/Introduction-to-BEAST2/]
- 40. Online Bayesian Phylodynamic Inference Tutorial [https://beast.community/online_inference]
- 41. Phylodynamic models [https://www.beast2.org/phylodynamic-models/]
- 42. Substitution model - Wikipedia [https://en.wikipedia.org/wiki/Substitution_model]
- 43. Phylogenetic and phylodynamic analyses of SARS-CoV-2 [https://pmc.ncbi.nlm.nih.gov/articles/PMC7366979/]
- 44. Models of DNA evolution - Wikipedia [https://en.wikipedia.org/wiki/Models_of_DNA_evolution]
- 45. Models of nucleotide substitution [https://cran.r-project.org/web/packages/jackalope/vignettes/sub-models.html]
- 46. Substitution Models - IQ-TREE [https://iqtree.github.io/doc/Substitution-Models]
- 47. Modeling Substitution Rate Evolution across Lineages and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11430275/]
- 48. Rate variation and estimation of divergence times using strict ... [https://bmcecolevol.biomedcentral.com/articles/10.1186/1471-2148-11-271]
- 49. Bayesian model-averaging of parametric coalescent ... [https://pubmed.ncbi.nlm.nih.gov/41272398/]
- 50. Towards a quantitative understanding of viral phylogeography [https://pmc.ncbi.nlm.nih.gov/articles/PMC3312803/]
- 51. Phylogenetic and phylodynamic approaches to understanding ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9028907/]
- 52. Phylogeographic diffusion in discrete space [https://beast.community/workshop_discrete_diffusion]
- 53. Animal Disease Surveillance in the 21st Century [https://www.frontiersin.org/journals/veterinary-science/articles/10.3389/fvets.2020.00176/full]
- 54. Estimating epidemic dynamics with genomic and time series ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12134936/]
- 55. Robust phylodynamic inference and model specification for ... [https://www.sciencedirect.com/science/article/pii/S1755436525000349]
- 56. Applications of Bayesian Phylodynamic Methods in a ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4735353/]
- 57. SARS-CoV-2 Variants: Genetic Insights, Epidemiological ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11818319/]
- 58. SARS-CoV-2 variants of concern as of 31 October 2025 - ECDC [https://www.ecdc.europa.eu/en/covid-19/variants-concern]
- 59. Measuring the impact of sow farm outbreaks with PRRS ... [https://www.frontiersin.org/journals/veterinary-science/articles/10.3389/fvets.2025.1545034/full]
- 60. Epidemiological analysis of porcine reproductive and ... [https://www.frontiersin.org/journals/veterinary-science/articles/10.3389/fvets.2025.1614039/full]
- 61. Variants and Genomic Surveillance | COVID-19 [https://www.cdc.gov/covid/php/variants/variants-and-genomic-surveillance.html]
- 62. MCMC diagnostics [https://sbfnk.github.io/mfiidd/mcmc_diagnostics.html]
- 63. Visual MCMC diagnostics using the bayesplot package - Stan [https://mc-stan.org/bayesplot/articles/visual-mcmc-diagnostics.html]
- 64. MCMC for Infectious Diseases Modeling - sismid [https://sismid.sph.emory.edu/modules/mcmc-II-infectious-diseases/index.html]
- 65. Three new methodologies for calculating the effective sample ... [https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-024-02412-1]
- 66. Phylodynamic Analysis [https://bio-protocol.org/exchange/minidetail?id=9625867&type=30]
- 67. High-Dimensional Parameter Spaces [https://www.emergentmind.com/topics/high-dimensional-parameter-spaces]
- 68. Sampling from high-dimensional, multimodal distributions ... [https://arxiv.org/html/2111.06871v2]
- 69. How to Diagnose and Resolve Convergence Problems - Stan [https://mc-stan.org/learn-stan/diagnostics-warnings.html]
- 70. Markov Chain Monte Carlo diagnostics - MATLAB [https://www.mathworks.com/help/stats/hamiltoniansampler.diagnostics.html]
- 71. Artificial neural network-based Hamiltonian Monte Carlo for ... [https://www.sciencedirect.com/science/article/abs/pii/S1540748924003985]
- 72. PrioriTree: a utility for improving phylodynamic analyses in BEAST - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC9841403/]
- 73. 2.2 Prior Specification and Related Theory | PrioriTree: an Interactive Utility for Improving Geographic Phylodynamic Analyses in BEAST [https://bookdown.org/jsigao/prioritree_manual/thorough-prior.html]
- 74. 1.3 Assessing Prior Sensitivity | PrioriTree: an Interactive Utility for Improving Geographic Phylodynamic Analyses in BEAST [https://bookdown.org/jsigao/prioritree_manual/assessing-prior-sensitivity.html]
- 75. Evolutionary and epidemic dynamics of COVID-19 in Germany ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11898094/]
- 76. Practical guidelines for Bayesian phylogenetic inference using ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10933576/]
- 77. inference with complex Bayesian phylodynamic models [https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1006546]
- 78. phylogenetic and Bayesian data integration using... phylodynamic [https://pubmed.ncbi.nlm.nih.gov/29942656/]
- 79. Model design for non-parametric phylodynamic inference ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8382123/]
- 80. Phylodynamic assessment of intervention strategies for the ... [https://www.nature.com/articles/s41467-018-03763-2]
- 81. Eight challenges in phylodynamic inference [https://www.sciencedirect.com/science/article/pii/S1755436514000437]
- 82. A simple method for data partitioning based on relative ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6118207/]
- 83. Selecting optimal partitioning schemes for phylogenomic ... [https://bmcecolevol.biomedcentral.com/articles/10.1186/1471-2148-14-82]
- 84. Bayesian phylodynamic inference with complex models [https://pubmed.ncbi.nlm.nih.gov/30422979/]
- 85. Bayesian phylodynamic inference with complex models - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC6258546/]
- 86. Phylodynamic Model Adequacy Using Posterior Predictive ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6368481/]
- 87. Cross-validation to select Bayesian hierarchical models in ... [https://bmcecolevol.biomedcentral.com/articles/10.1186/s12862-016-0688-y]
- 88. A Note on Posterior Predictive Checks to Assess Model Fit ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5096987/]
- 89. 7.1 Posterior predictive checking | An Introduction to ... [https://bookdown.org/kevin_davisross/bayesian-reasoning-and-methods/posterior-predictive-checking.html]
- 90. Bayesian cross-validation of geostatistical models [https://www.sciencedirect.com/science/article/abs/pii/S2211675319301459]
- 91. Comparative phylodynamics reveals the evolutionary ... [https://pubmed.ncbi.nlm.nih.gov/35677574/]
- 92. Comparative phylodynamics reveals the evolutionary ... [https://pure.kfas.org.kw/en/publications/comparative-phylodynamics-reveals-the-evolutionary-history-of-sar]
- 93. Updated Insights into the Phylogenetics, Phylodynamics ... [https://www.mdpi.com/1999-4915/16/2/171]
- 94. Variant-specific introduction and dispersal dynamics of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10180688/]
- 95. Applications of Bayesian Phylodynamic Methods in a ... [https://www.frontiersin.org/journals/microbiology/articles/10.3389/fmicb.2016.00067/full]
- 96. Common Methods for Phylogenetic Tree Construction and ... [https://www.mdpi.com/2306-5354/11/5/480]
- 97. Phylogenetic Analyses: A Toolbox Expanding towards ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC2375977/]
- 98. Assessing phylogenetic confidence at pandemic scales [https://www.nature.com/articles/s41586-025-09567-x]
- 99. Model misspecification misleads inference of the spatial ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10089176/]
- 100. Bayesian Phylodynamic Inference of Multitype Population ... [https://pubmed.ncbi.nlm.nih.gov/40458956/]
- 101. How does date-rounding affect phylodynamic inference for ... [https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1012900]
- 102. Application of Phylodynamic Tools to Inform the Public Health ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10131930/]
- 103. Application of Phylodynamic Tools to Inform the Public ... [https://experts.nau.edu/en/publications/application-of-phylodynamic-tools-to-inform-the-public-health-res]
- 104. Advances in CRISPR‐Cas9 in lineage tracing of model animals [https://pmc.ncbi.nlm.nih.gov/articles/PMC12205011/]
- 105. How to Pick the Best CRISPR Data Analysis Method for ... [https://www.synthego.com/guide/how-to-use-crispr/analysis-methods/]
- 106. Single-cell lineage tracing by integrating CRISPR-Cas9 ... [https://www.nature.com/articles/s41467-020-16821-5]
- 107. Dual-nuclease single-cell lineage tracing by Cas9 and ... [https://www.sciencedirect.com/science/article/pii/S2211124724014566]
- 108. A Survey of Validation Strategies for CRISPR-Cas9 Editing [https://www.nature.com/articles/s41598-018-19441-8]
- 109. Next generation lineage tracing and its applications ... [https://www.nature.com/articles/s41540-025-00542-w]